






Data does not create value on its own. It only becomes valuable once it is shaped, moved, validated, and placed where people can actually use it. Most teams discover this the hard way when:
- Dashboards lag
- Reports contradict each other.
- Sales and marketing argue over numbers.
- Engineers spend more time fixing pipelines than building new ones.
At the center of all this friction sits a quiet but critical question: how should data move across systems? That question leads us to three approaches that define modern data integration: ETL, ELT, and Reverse ETL.
They are often discussed as tools or trends. But in reality, they are architectural choices that shape how organizations trust and activate data. We understand your curious mind might want to know how. That is exactly the purpose of this guide! It explores each approach in depth. Not just what they are, but how they are actually used, and why integration decisions matter more today than ever before.
Why Data Integration Is No Longer Just a Backend Concern
A decade ago, data integration lived in the shadows. It was something engineers handled quietly. Business teams never really got to know it, as they only saw the final reports. That separation no longer exists in modern times. Today, data powers:
- Revenue forecasting
- Customer personalization
- Product experimentation
- Operational planning
When integration breaks, the impact is immediate and visible. Modern organizations rely on dozens, sometimes hundreds, of data sources. Each source evolves independently. Schemas change. APIs fail. Data volumes spike without warning. This complexity has forced teams to rethink how data pipelines are built, monitored, and maintained. ETL, ELT, and Reverse ETL emerged from this need. Each one solves a different integration problem. Let us now understand each of these bit by bit!
ETL: The Original Workhorse of Data Integration
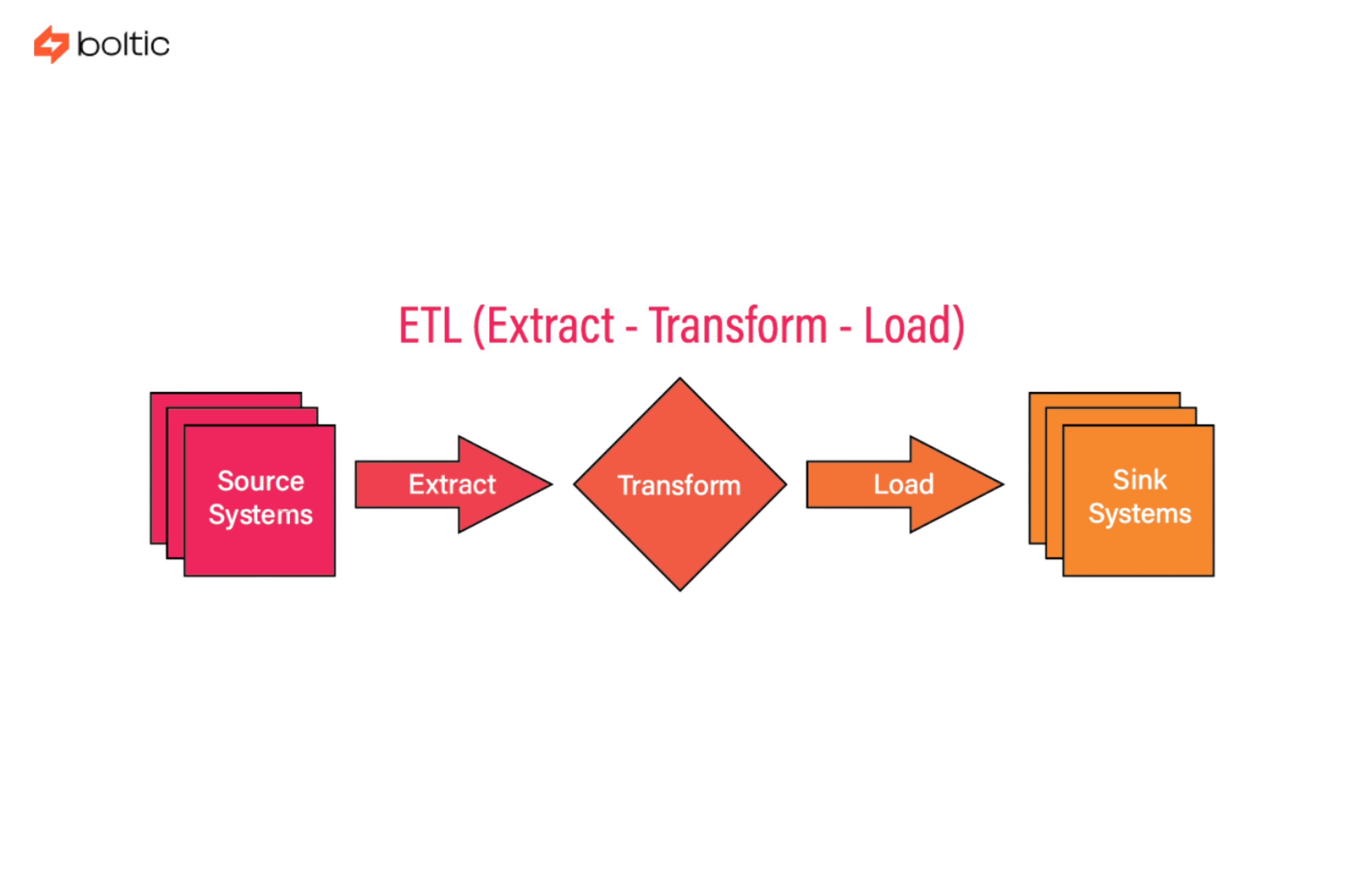
ETL, when expanded, becomes Extract, Transform, Load. It is the oldest and most established integration pattern still in use today. In an ETL workflow, data is extracted from source systems. It is then transformed into a separate processing layer. Only after meeting strict requirements is it loaded into a destination system.
This sequence was not accidental. Early data warehouses had limited storage and compute capacity. They could not afford to ingest raw, unfiltered data. ETL was designed to protect the warehouse.
How ETL Works in Practice
An ETL pipeline typically includes:
- Data extraction using connectors or batch jobs
- A transformation layer for cleaning, filtering, and reshaping
- A controlled loading process into the target system
Transformations may include:
- Data type normalization
- Aggregations
- De-duplication
- Removal or masking of sensitive fields
Only validated data moves forward.
Where ETL Still Makes Sense Today
Despite newer approaches, ETL has not disappeared. It remains valuable in environments where control outweighs flexibility. Common ETL use cases include:
- Regulated industries with strict compliance requirements
- Legacy systems that cannot handle raw ingestion
- Financial or healthcare data pipelines
- Workflows involving heavy pre-processing
Because data is transformed before storage, ETL reduces downstream risk. That predictability is still important in many organizations. Now that we are all covered with ETL, let us tell you about the other term, ELT.
ELT: Designed for the Scale of Modern Data
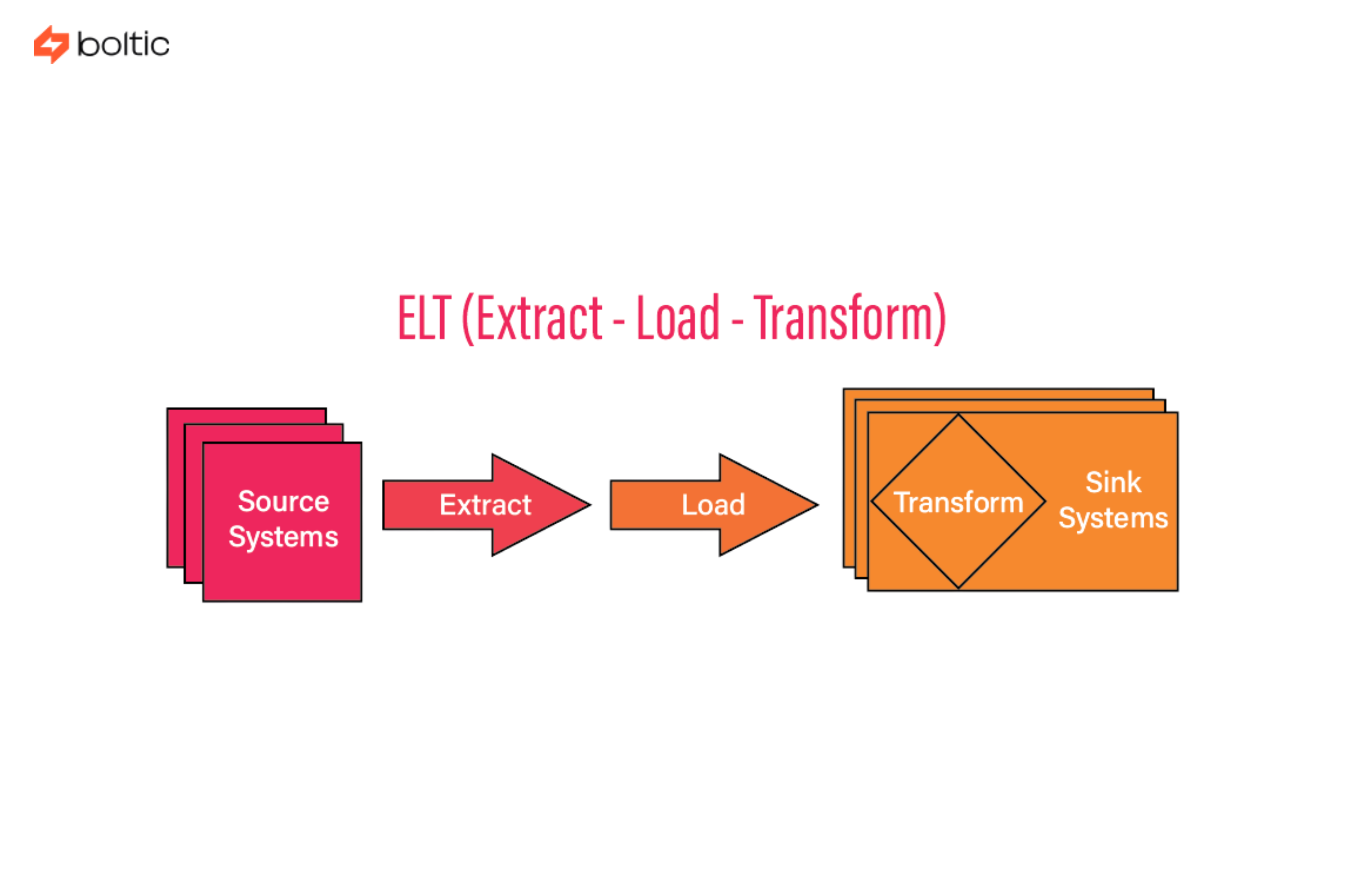
ELT stands for Extract, Load, Transform. The difference is subtle in wording, but massive in impact. With ELT, raw data is loaded directly into the data warehouse. Transformations happen afterward, inside the warehouse itself. This approach became viable only with the rise of cloud-native data platforms. Modern warehouses are built for scale. They can store massive volumes of raw data. They can process transformations in parallel. ELT takes advantage of that power.
How ELT Pipelines Operate
In an ELT architecture:
- Data is extracted from source systems with minimal processing
- Raw data is loaded directly into the warehouse
- Transformations are executed using SQL or warehouse-native tools
Instead of a single transformation step, ELT supports many. Teams can build multiple transformation layers on top of the same raw data. This creates flexibility that ETL cannot easily match.
Why ELT Became the Default for Modern Analytics
ELT aligns with how businesses ask questions today.
- Questions change.
- Metrics evolve.
- New teams want access to historical data.
ELT supports this reality by preserving raw data.
Key advantages include:
- Faster ingestion at scale
- Support for structured and semi-structured data
- Ability to reprocess historical datasets
- Lower operational complexity
For product analytics, event data, and experimentation, ELT is often the natural choice.
ETL vs ELT: Detailed Side-by-Side Comparison
Now that you have understood both ETL and ELT individually, it is time for a comparison, in order to make things clearer:
Reverse ETL: Activating Data Beyond Analytics
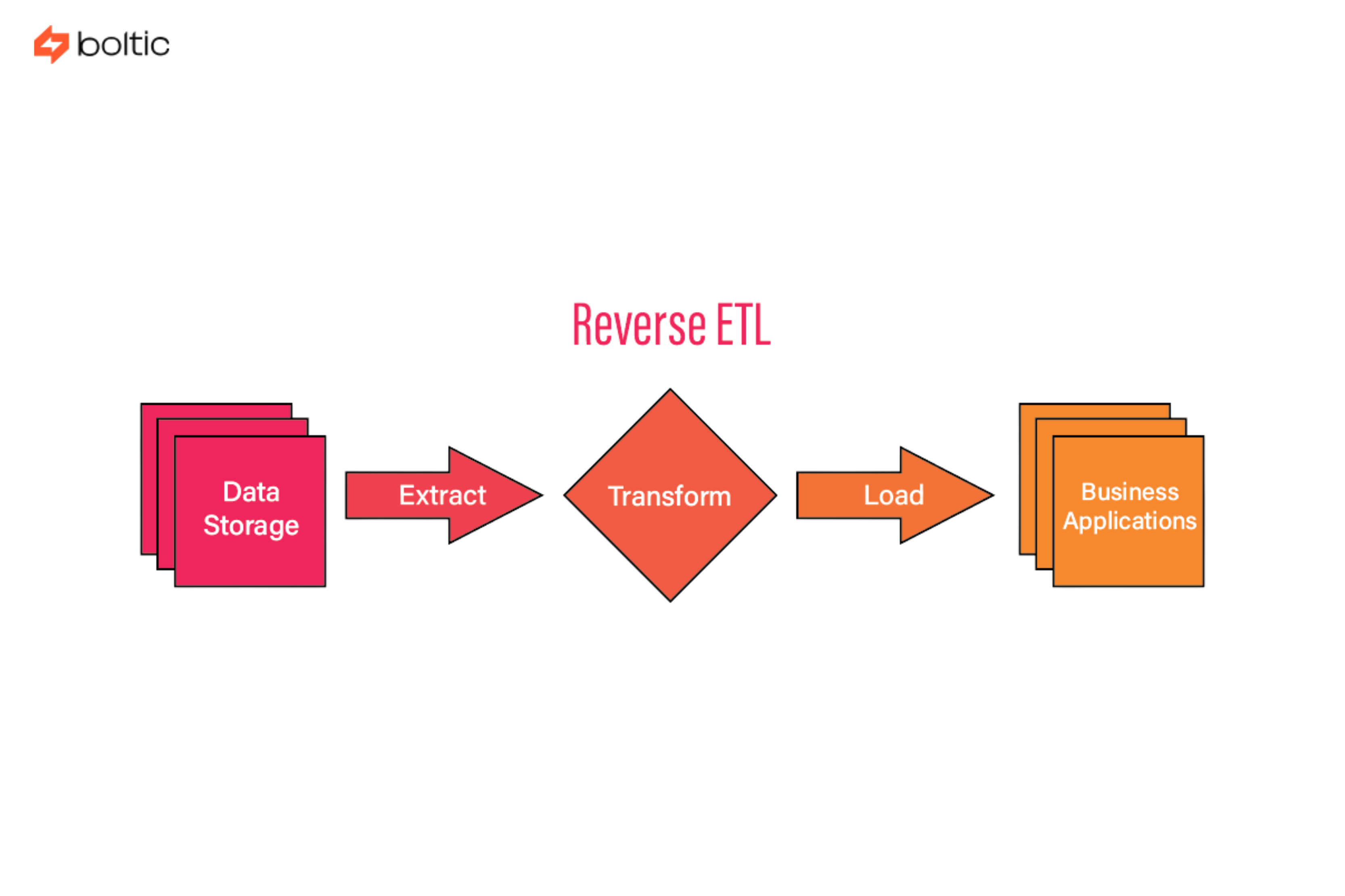
ETL and ELT focus on getting data into the warehouse. Reverse ETL focuses on getting data out. This shift reflects a broader change in how organizations use data. Analytics alone is not enough. Insights must reach operational systems. And they must arrive in a usable, trustworthy form. That is the role of Reverse ETL. Now, let us get into the working of it!
What Reverse ETL Actually Does
Reverse ETL takes curated data models from the warehouse and syncs them back into business tools.
These tools may include:
- CRM platforms
- Marketing automation systems
- Customer support tools
- Advertising platforms
Instead of exporting CSVs or building one-off scripts, Reverse ETL creates continuous, automated data flows. The warehouse becomes the source of truth, and operational tools become data consumers.
Why Reverse ETL Changed How Teams Work
Reverse ETL eliminates a common gap. Analytics teams often know something before everyone else. But that knowledge rarely reaches frontline teams in time. Reverse ETL closes that loop. It enables:
- Real-time segmentation for marketing
- Priority scoring for sales teams
- Risk signals for customer success
- Personalization at scale
When data flows reliably, decisions improve.
Integration Use Cases Across the Data Lifecycle
Understanding ETL, ELT, and Reverse ETL is easier when viewed through real-world use cases.
ETL Use Cases
ETL remains relevant where predictability is essential.
Typical scenarios include:
- Regulatory reporting
- Financial reconciliations
- Secure data processing pipelines
- Legacy system integrations
In these environments, preventing bad data from entering storage is critical.
ELT Use Cases
ELT excels where volume and variety dominate. Common ELT use cases include:
- Event tracking and telemetry
- Product usage analytics
- Data science experimentation
- Multi-source BI pipelines
Raw data availability enables faster iteration.
Reverse ETL Use Cases
Reverse ETL focuses on activation. High-impact use cases include:
- Syncing churn risk scores into CRMs
- Feeding customer segments into marketing tools
- Updating account health metrics for support teams
- Powering personalization engines
These workflows turn analytics into action.
Why Integration Reliability Matters More Than Ever
As data stacks grow, so does fragility. Pipelines break quietly. Schema changes go unnoticed.
Downstream tools consume stale or incorrect data. When this happens, trust erodes. Reliable integration is not optional.
It requires:
- Monitoring freshness and volume
- Detecting schema changes early
- Understanding downstream impact
Without observability, even well-designed ETL or ELT pipelines fail silently.
Choosing the Right Integration Strategy
There is no single correct architecture. Most organizations use a combination of approaches. The right mix depends on:
- Data volume and velocity
- Compliance requirements
- Team structure and ownership
- Business activation needs
ETL provides safety. ELT provides scale. Reverse ETL provides impact. The challenge is orchestrating them together without losing trust in the data.
Integration as a Competitive Advantage
Data integration is no longer plumbing. It is infrastructure for decision-making. Organizations that move data reliably move faster. They adapt quicker. They argue less over numbers. ETL, ELT, and Reverse ETL are not competing ideas. They are complementary tools in a modern data strategy. When implemented thoughtfully and monitored carefully, they allow data to flow where it matters most. And that is where data finally delivers on its promise.
As organizations adopt a mix of ETL, ELT, and reverse ETL, Boltic helps ensure data remains reliable! It monitors pipeline health, detecting schema and freshness issues while also preventing integration failures from reaching downstream teams. No matter which integration pattern you use, Boltic helps you trust the data flowing through them.
drives valuable insights
Organize your big data operations with a free forever plan
An agentic platform revolutionizing workflow management and automation through AI-driven solutions. It enables seamless tool integration, real-time decision-making, and enhanced productivity
Here’s what we do in the meeting:
- Experience Fynd Boltic's features firsthand.
- Learn how to automate your data workflows.
- Get answers to your specific questions.



