






Welcome to our comparison of Spark vs Kafka, two powerful data processing and streaming technologies. With the increasing popularity of big data, it has become more important than ever to understand the different technologies that can help you process, store, and analyze this data. In this article, we will dive into the key differences between these two platforms and explore the unique capabilities of each one. We will also discuss the typical use cases for each technology and provide some guidance on when to use one over the other. By the end of this comparison, you should have a good understanding of the pros and cons of each platform and be able to make an informed decision about which one is best suited for your needs.
What is Apache Kafka?

Apache Kafka is an open-source stream processing platform developed by the Apache Software Foundation. It is used for building real-time data pipelines and streaming applications. It is written in Scala and Java and is often used for building real-time data pipelines and streaming applications. It is often used for log aggregation and data integration between different systems. It is also used to build real-time streaming applications. It collects data from different sources and routes it to different consumers. This process is known as streaming. It is a distributed streaming platform. It is designed to be fault-tolerant and highly available. It is designed to handle large volumes of data and process it in near real-time. It has a distributed commit log, which stores the data and is replicated across multiple nodes.
It is designed to be horizontally scalable and can handle many producers and consumers. It provides a unified, high-throughput, low-latency platform for the real-time handling of data feeds. It is used for various use cases, including collecting data from multiple systems, building real-time streaming applications, and providing the foundation for a distributed system. It is used in applications such as messaging, website activity tracking, data integration, log aggregation, and monitoring. It is a powerful tool for building real-time data pipelines and streaming applications. It is designed to be fault-tolerant and highly available, and can handle large volumes of data. It provides the foundation for a distributed system and can be used to build real-time streaming applications.
Components of Apache Kafka

Apache Kafka consists of four core components:
1. Kafka Broker:
The Kafka Broker manages topics and partitions. It is responsible for managing the storage of messages and replicating them across a cluster of machines.
2. Kafka Producer:
The Kafka Producer is responsible for writing messages to the Kafka broker. It is responsible for the delivery of messages to the Kafka broker.
3. Kafka Consumer:
The Kafka Consumer is responsible for reading messages from the Kafka broker. It is responsible for consuming messages from the Kafka broker.
4. Kafka Connect:
Kafka Connect is responsible for integrating Kafka with other systems. It integrates Kafka with databases, message queues, and other data sources.
These four components of Apache Kafka work together to provide a powerful platform for stream processing.
Advantages of Apache Kafka

It is designed to handle a high volume, high throughput, and low latency data streams and has a strong track record of being used in mission-critical environments.
Here are some of the key advantages of using Apache Kafka
1. Scalability
Kafka is horizontally scalable, meaning that it can handle an increase in traffic by adding more brokers to the cluster. This makes it an ideal choice for handling high-volume data streams.
2. Durability
Kafka stores all published records for a configurable amount of time, making it possible to retain a record of all events in the system. This makes it easy to rebuild materialized views or to re-process historical data for business intelligence purposes.
3. High performance
Kafka has been designed to handle high throughput and low latency data streams, making it a good choice for real-time data processing. It can process millions of records per second, making it suitable for high-volume data streams.
4. Fault tolerance
Kafka is designed to handle failures gracefully. In the event of a failure, it can automatically recover without needing manual intervention.
5. Multi-subscriber
Kafka allows multiple subscribers to consume the same data stream, making it possible to build multiple real-time applications that all consume the same data.
6. Publish-subscribe model
Kafka uses a publish-subscribe model, where producers write data to Kafka topics, and consumers read from those topics. This makes it easy to build event-driven architectures, where different parts of the system can react to events as they occur.
7. Open source
Kafka is an open-source project that is free to use and modify. This makes it an attractive option for organizations that want to avoid the costs associated with proprietary solutions.
8. Integration with other tools
Kafka has a wide range of integrations with other tools and technologies, making it easy to incorporate them into existing systems. It can be integrated with tools such as Hadoop, Spark, and Flink for data processing and with message brokers such as RabbitMQ and ActiveMQ.
9. Flexible data retention
Kafka allows for flexible data retention policies, allowing users to configure how long data is retained in the system. This makes it possible to store data for as long as needed, whether for a few hours or several years.
10. Easy to operate
Kafka is designed to be easy to operate, with a straightforward architecture. It has a command line interface and well-documented API, making it easy to start and integrate into existing systems.
11. Wide adoption
Kafka has a large and active community of users and developers, making it well-supported and widely adopted. This means that a wealth of documentation, support, and third-party tools is available for Kafka users.
12. Stream processing
Kafka has built-in support for stream processing, making it possible to build real-time streaming applications that process data as it is produced. This makes it an ideal choice for scenarios where data needs to be processed in near real-time, such as fraud detection or event-triggered marketing campaigns.
13. Multi-language support
Kafka has clients in various programming languages, including Java, Python, C++, and C#. This makes it easy to integrate Kafka into a variety of systems and to build applications in the language of your choice. Apache Kafka is a powerful tool for building real-time data pipelines and streaming applications. Its scalability, durability, high performance, and fault tolerance make it well-suited for mission-critical environments, and its publish-subscribe model and multi-subscriber capabilities make it easy to build event-driven architectures. Its open-source nature also makes it an attractive option for organisations that want to avoid the costs associated with proprietary solutions.
What is Kafka Workflow?
Kafka Workflow is a distributed streaming platform that can be used to build and manage real-time data pipelines and streaming applications. It is a platform for building and deploying distributed applications and processing data streams in real-time. Kafka Workflow simplifies the development and deployment of streaming applications by providing an easy-to-use, scalable, and reliable platform. Kafka Workflow is built on the popular open-source streaming platform Apache Kafka, which is used to process large amounts of real-time data.
With Kafka Workflow, users can build, manage and deploy streaming applications with minimal effort. It provides a distributed and fault-tolerant framework for handling streaming data. Kafka Workflow enables users to create real-time data pipelines, process data streams in real time, and deploy streaming applications with minimal effort.
The architecture of Kafka Workflow consists of four components:

1. Producer:
The producer sends data to the Kafka broker. It can be a web server, a mobile application, a database, or other systems that produce data.
2. Kafka Broker:
The Kafka broker is responsible for storing the data from the producer and replicating it to other brokers as needed. It is responsible for routing data from producers to consumers.
3. Consumer:
The consumer is responsible for consuming data from the Kafka broker. It can be a web server, a mobile application, a database, or any other system that consumes data.
4. Stream Processor:
The stream processor is responsible for processing the data from the Kafka broker. It can be used to transform the data, filter it, or to apply business logic.
Kafka Workflow enables users to easily build and manage data pipelines and streaming applications with minimal effort. It provides a reliable, scalable, and easy-to-use platform for building and deploying streaming applications. By leveraging the power of Apache Kafka, Kafka Workflow makes it easy to build and deploy real-time data pipelines and streaming applications.
What is Apache Spark?

Apache Spark is an open-source data processing engine that processes large-scale data sets. It is a powerful tool for data manipulation, analysis, and machine learning, and it is quickly becoming the go-to platform for big data processing. The Apache Software Foundation developed Apache Spark, written in the Scala programming language. It allows users to quickly process large amounts of data by parallelising operations across multiple computers. This makes Apache Spark much faster than traditional data processing methods.
It uses an in-memory computing model, allowing the system to process data quickly without writing it to storage. This makes it ideal for complex analytics, streaming data, and machine learning. It also makes it possible to run applications on large clusters of computers. It is often used for large-scale data processing tasks such as machine learning, streaming analytics, data mining, natural language processing, and graph processing. It can also be used for interactive ad-hoc queries and ETL pipelines. It is highly versatile and can be used for many tasks. It is widely used for data analysis and machine learning due to its ability to process large amounts of data quickly. Apache Spark has become increasingly popular in recent years, and many companies, including Google, Facebook, Amazon, and Twitter, now use it. It has become the go-to platform for big data processing and is revolutionising how we process data.
Advantages of Apache Spark
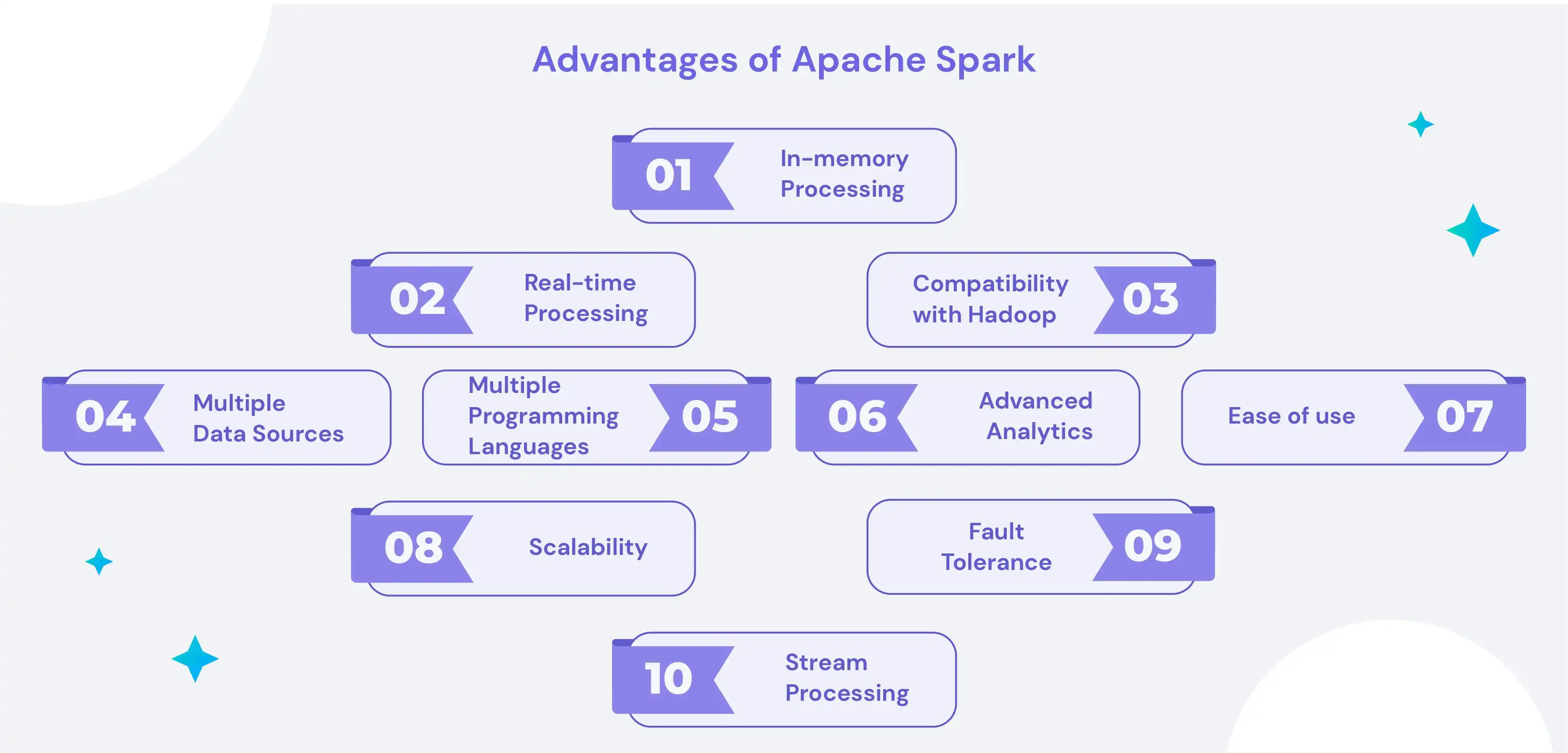
Here are some of the key advantages of using Apache Spark:
1) In-memory processing
One of the biggest advantages of Spark is its ability to process data in memory, which allows it to be much faster than traditional disk-based systems like Hadoop. This makes it an ideal choice for scenarios where speed is required, such as real-time stream processing or interactive data exploration.
2) Real-time processing
Spark can process data in real time, making it suitable for scenarios where data needs to be processed as it is produced. This makes it a good choice for fraud detection, event-triggered marketing campaigns, and Internet of Things (IoT) applications.
3) Compatibility with Hadoop
Spark is built on top of the Hadoop Distributed File System (HDFS) and is designed to be compatible with the Hadoop ecosystem. This means that it can easily integrate with other Hadoop-based tools and technologies, making it a natural choice for organizations already using Hadoop.
4) Multiple data sources
Spark can read data from various sources, including HDFS, Cassandra, and Amazon S3. This makes it a flexible choice for organizations storing data in multiple systems.
5) Multiple programming languages
Spark has APIs for several programming languages, including Java, Python, and Scala. This makes it easy to use Spark with your choice's language and integrate it with existing systems.
6) Advanced analytics
Spark includes libraries for advanced analytics tasks such as machine learning, graph processing, and stream processing. This makes it a powerful choice for organizations that need to perform complex data processing and analytics tasks.
7) Ease of use
Spark has a simple and intuitive API, making it easy to start and use. It also has many helpful resources and a large community of users, making getting help and support easier when needed.
8) Scalability
Spark is highly scalable, making it possible to process data on a cluster with thousands of nodes. This makes it an ideal choice for organizations that need to quickly process large amounts of data.
9) Fault tolerance
Spark includes built-in fault tolerance capabilities, which means it can recover from failures without needing manual intervention. This makes it a good choice for mission-critical applications that need to be highly available.
10) Stream processing
Spark has built-in support for stream processing, making it possible to build real-time streaming applications that process data as it is produced. This makes it an ideal choice for scenarios where data needs to be processed in near real-time, such as fraud detection or event-triggered marketing campaigns.
11) Graph processing
Spark includes a library called GraphX, which allows users to process graph data and perform graph-parallel computations. This makes it a good choice for organizations that need to perform graph analytics tasks.
12) Machine learning
Spark includes a library called MLlib, which allows users to perform machine learning tasks at scale. This makes it a good choice for organizations that need to build and deploy machine learning models on large datasets.
13) Interactive data exploration
Spark includes a library called Spark SQL, which allows users to perform interactive data exploration and analysis using SQL. This makes it a good choice for organizations that need to perform ad-hoc data analysis tasks.
Apache Spark has several advantages, making it a powerful choice for big data processing and analytics. Its in-memory processing, real-time processing, compatibility with Hadoop, support for multiple data sources and programming languages, and advanced analytics capabilities make it a versatile choice for many use cases. Its scalability, fault tolerance, and support for stream processing, graph processing, machine learning, and interactive data exploration make it an attractive choice for many organizations.
What is Spark Workflow?
Spark Workflow is a cloud-native, distributed workflow engine that enables developers to create and manage complex workflows between different services, applications, and systems. It is a powerful and flexible platform that helps organizations quickly and easily build powerful workflows that are reusable and repeatable. It helps businesses to create intricate, repeatable workflows with minimal effort. It features a graphical designer that allows developers to easily create workflow diagrams and then deploy them with a few simple clicks.
In addition, there are tools available for testing and debugging the workflows and tracking their progress. The basic workflow in Spark involves creating a Spark application, loading data into Spark, transforming the data, and running actions on the transformed data.
Here is a high-level overview of this process:
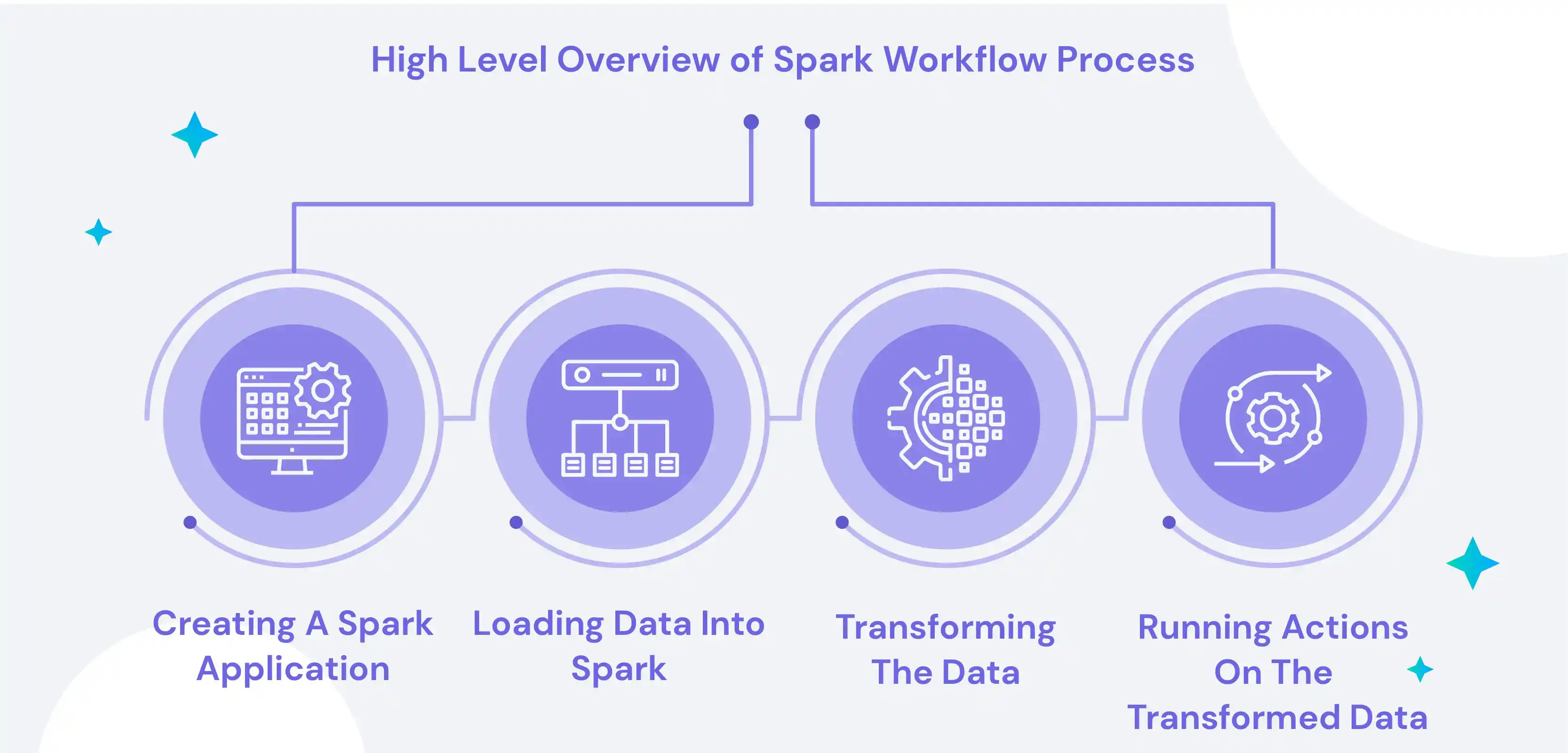
A) Creating a Spark application:
A Spark application is a self-contained program built using the Spark API. It can be written in Java, Python, Scala, or any other language supported by Spark.
B) Loading data into Spark:
The first step in a Spark application is to load the data that needs to be processed. This can be done by reading data from external storage systems such as HDFS or Cassandra or generating data within the Spark application.
C) Transforming the data:
Once the data has been loaded, it can be transformed using the various transformation functions provided by Spark. These functions allow users to filter, aggregate and manipulate the data in various ways.
D) Running actions on the transformed data:
Once the data has been transformed, users can run various actions on it to compute a result. These actions include counting the number of records, finding the maximum value, or collecting the data for the driver program.
Here is a high-level overview of the Spark architecture:

A) Driver program:
The driver program is the main entry point for a Spark application. It is responsible for creating the SparkContext, which is used to connect to the Spark cluster, and for creating RDDs (Resilient Distributed Datasets) or DataFrames, which are distributed data structures that Spark can process.
B) Executors:
Executors are processes that run on worker nodes and are responsible for executing tasks in a Spark application. Each executor is associated with a single Spark application and is responsible for running the assigned tasks.
C) Worker nodes:
Worker nodes are the servers in a Spark cluster that run the executors. There is one worker node for each executor, and each worker node runs one or more executors.
D) Cluster manager:
The cluster manager is responsible for allocating resources to Spark applications and scheduling tasks to execute on the executors. Spark supports several cluster managers, including Apache Mesos, Hadoop YARN, and the standalone Spark cluster manager.
Spark workflow involves creating a Spark application, loading data into Spark, transforming the data, and running actions on the transformed data. The Spark architecture consists of a driver program, executors, worker nodes, and a cluster manager, which work together to execute Spark applications and process data.
Understanding Apache Kafka and Apache Spark Differences
Apache Kafka and Apache Spark are both powerful tools for data processing, but they are designed for different use cases. Kafka is a distributed event streaming platform used to build real-time data pipelines and streaming applications. It is designed to handle high volume, high throughput, and low latency data streams and is particularly well-suited for scenarios where data needs to be processed in near real-time.
On the other hand, Spark is a distributed computing system for big data processing and analytics. It is designed to be fast and flexible and can handle data processing tasks of any scale. It is particularly well-suited for scenarios where data needs to be transformed and analysed in batch mode, such as extract, transform, and load (ETL) processes.

1. ETL
Kafka is often used as the source of data for a Spark application. It can stream data in real time from various sources, and Spark can be used to process the data and load it into a data warehouse or other storage system. This allows organizations to build real-time ETL pipelines that can process and analyze data as it is produced. To summarize, Kafka is a good choice for building real-time data pipelines and streaming applications, while Spark is a good choice for ETL processes and batch data processing and analytics. They can be used together to build real-time ETL pipelines that process and analyze data as it is produced.
2. Latency
Latency refers to the time it takes for data to be processed and made available for consumption. Low latency is generally preferred in data processing, so data is available for consumption more quickly. Apache Kafka is designed to handle a high volume, high throughput, and low latency data streams, making it a good choice for scenarios where data needs to be processed in near real-time. It uses a publish-subscribe model, where producers write data to Kafka topics, and consumers read from them. This allows for real-time processing, as data is made available for consumption as soon as it is produced.
On the other hand, Apache Spark is a distributed computing system designed for big data processing and analytics. It is generally slower than Kafka when it comes to processing data in real time, as it is designed to handle larger volumes of data and is optimized for batch processing. However, Spark offers several features that can help to reduce latency, such as in-memory processing and support for stream processing. Kafka is generally considered to have lower latency than Spark, as it is designed specifically for real-time data processing. However, Spark offers several features that can help in reducing latency, and it is a good choice for batch data processing and analytics.
3. Recovery
Recovery refers to the ability of a system to recover from failures and continue operating without manual intervention. Apache Kafka and Spark have built-in fault tolerance capabilities that allow them to recover from failures and continue processing data. In Kafka, data is stored on a distributed cluster of brokers, and the data is replicated across multiple brokers for fault tolerance. If a broker goes down, the data can be recovered from one of the replicas, allowing the system to continue operating without manual intervention. Kafka also includes features such as automatic leader election and consumer group rebalancing, which help to ensure that the system can recover from failures and continue processing data.
Spark also has built-in fault tolerance capabilities, which allow it to recover from failures and continue processing data. In Spark, data is stored in RDDs (Resilient Distributed Datasets), distributed data structures that can be processed in parallel. If a worker node goes down, the data stored in the RDD can be recovered from other worker nodes, allowing the system to continue operating without manual intervention. Spark also includes features such as the automatic recovery of failed tasks and support for straggler mitigation, which help to ensure that the system can recover from failures and continue processing data. Kafka and Spark have built-in fault tolerance capabilities that allow them to recover from failures and continue processing data.
4. Processing Type
Kafka is primarily designed for real-time data processing, while Spark is primarily designed for batch data processing. However, both tools can be used for a wide range of data processing tasks and can be used together to build real-time data pipelines that process and analyze data as it is produced.
5. Programming Languages Supported
Kafka does not support any programming language for data transformation, while Spark supports various programming languages and frameworks, allowing it to do more than just interpret data. With Spark, you can use existing machine learning frameworks and process graphs, providing more data transformation and analysis capabilities.
Kafka Streams use-cases
Apache Kafka Streams is a client library for building applications and microservices, where the input and output data are stored in a Kafka cluster. It is designed to allow easy and efficient real-time data processing using the publish-subscribe model of Kafka.
Here are some common use cases for Kafka Streams:
1. Real-time data processing
Kafka Streams is well-suited for real-time scenarios where data needs to be processed, such as fraud detection, event-triggered marketing campaigns, and Internet of Things (IoT) applications.
2. Microservices
It can be used to build microservices that process and transmit data between different systems.
3. Data integration
It can be used to integrate data from multiple sources and make it available for processing and analysis.
4. Stream processing
It can be used to build stream processing applications that process data as it is produced.
5. Data filtering and transformation
It can be used to filter and transform data as it is processed, making it easy to extract the relevant information and prepare it for further analysis.
6. Machine learning
It can be used to build real-time machine learning applications that process data in near real-time and make predictions or recommendations based on that data.
7. Anomaly detection
It can be used to build applications that monitor data streams and detect anomalies in real-time, such as unusual spikes in traffic or unusual patterns in user behaviour.
8. Data Enrichment
It can also be used to build data enrichment applications. This involves consuming data from topics in Kafka and enriching it with additional data from external sources. This can add additional context or join data from multiple topics to provide a unified view. Kafka Streams provides APIs for consuming data from topics and transforming it into the desired format. It also supports windowing and stateful processing, making it easy to build applications that enrich data in real-time.
9. Complex Event Processing
Kafka Streams can also be used to build complex event-processing applications. This involves consuming data from topics in Kafka and processing it to detect patterns and correlations. This can be used to detect anomalies in the data or to trigger events based on certain conditions. Kafka Streams provides APIs for consuming data from topics and transforming it into the desired format. It makes it easy to detect patterns and correlations over a given timeframe. Kafka Streams also provides stateful processing support, making it easy to maintain an aggregated view over time.
10. Online Data Aggregation
Kafka Streams can also be used to build online data aggregation applications. These applications consume data from topics in Kafka and aggregate it into an aggregated view. This can be used to build applications that provide real-time statistics and dashboards or to aggregate data across multiple topics to provide a unified view of data. Kafka Streams provides APIs for consuming data from topics and aggregating it into the desired format.
Kafka Streams is a useful tool for building applications and microservices that need to process data in real-time, integrate data from multiple sources, perform stream processing, filter and transform data, perform machine learning tasks, and detect anomalies.
Spark Streaming use-cases
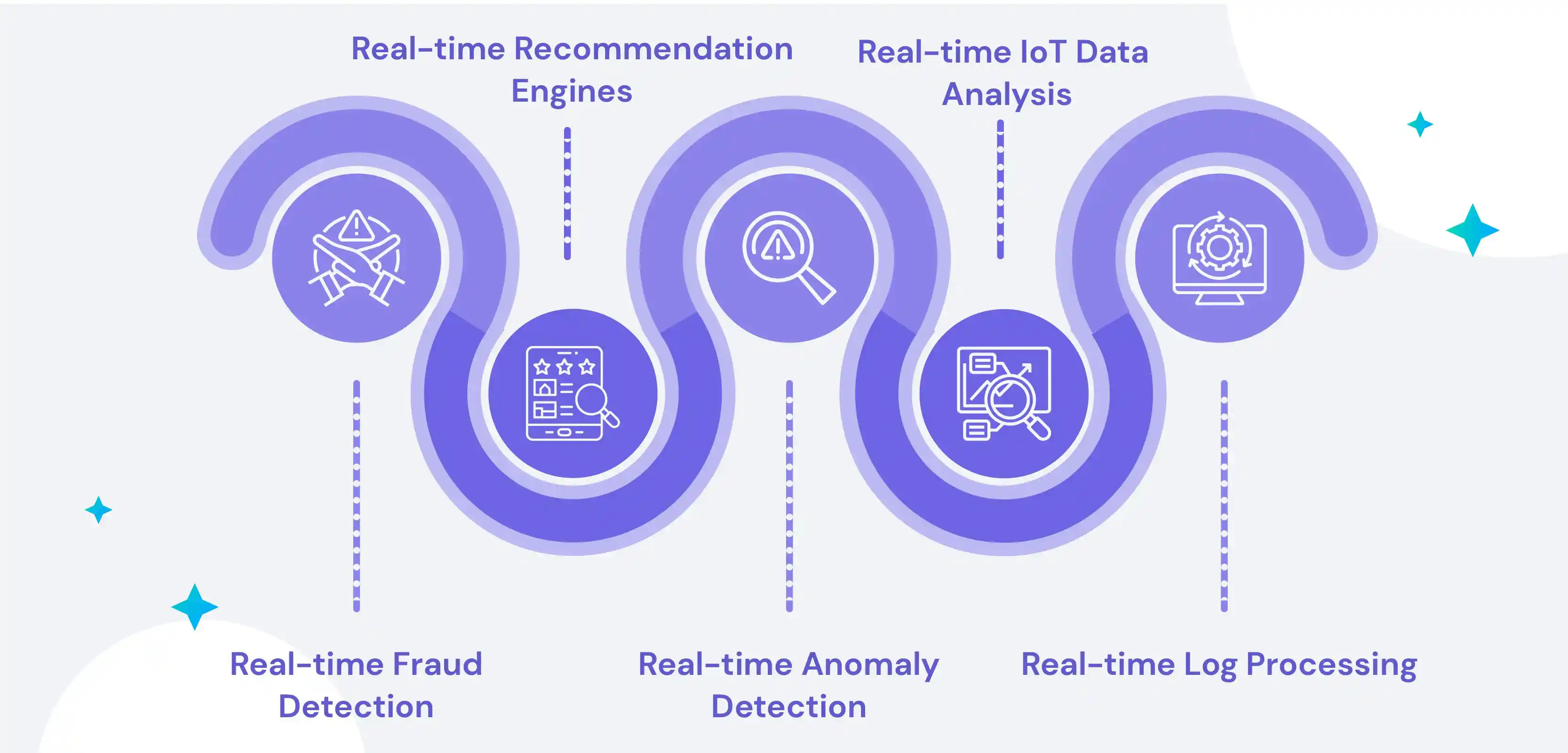
Spark streaming is a powerful tool for processing large amounts of data in real-time, making it an ideal solution for many use cases. As more companies move towards data-driven decisions and insights, real-time data processing and analysis are becoming increasingly important. Spark streaming can be used to build streaming applications that can process data from multiple sources, including popular streaming sources such as Kafka, Amazon Kinesis, and Flume. This makes it a great choice for real-time applications that need to process data streams from multiple sources.
Data Streaming use cases
1. Real-time Fraud Detection
Fraud is a major issue for businesses, and detecting fraud in real-time is essential for preventing losses and maintaining customer trust. As fraudsters get more sophisticated, traditional fraud detection methods may not be enough. It can be used to build streaming applications that detect fraud in real-time by quickly and efficiently analysing data from multiple sources quickly and efficiently.
2. Real-time Recommendation Engines
Real-time recommendation engines are becoming increasingly popular for e-commerce and streaming media applications. Spark streaming can quickly analyse data from multiple sources in real time and generate personalised recommendations for each user. This can help businesses increase customer engagement and sales by providing relevant and timely recommendations.
3. Real-time Anomaly Detection
Anomaly detection is important for detecting suspicious activity or events in real-time. Spark streaming can quickly analyse data from multiple sources and detect real-time anomalies. This can be used to detect unusual patterns in user behaviour or to detect suspicious transactions that may indicate fraud.
4. Real-time IoT Data Analysis
The Internet of Things (IoT) is rapidly becoming a reality, and there is a huge opportunity for businesses to leverage this technology to gain insights into customer behaviour and optimise operations. It can quickly analyse data from multiple sources in real time and extract useful insights from IoT data. This can be used to improve customer experience and increase operational efficiency.
5. Real-time Log Processing
Logs are an important data source for many applications, and analysing log data in real-time can help businesses gain valuable insights. Spark streaming can quickly process streaming log data in real-time and extract useful insights. This can detect log data anomalies, analyse user behaviour, and optimise system performance. Spark streaming is a powerful tool for processing real-time streaming data and can be used in many cases. It can help businesses gain valuable insights and make more informed decisions quickly and efficiently.
Kafka and Spark Comparison Table
Here is a comparison table that summarises the key differences between Apache Kafka and Apache Spark:
{{Kafka="/components"}}
Choose the right implementation partner

Boltic is a no-code data transformation tool that is designed to help users transform and integrate data from multiple sources without the need for coding. It is intended to make it easier for non-technical users to perform data transformation tasks and to streamline the process of integrating data from different systems.
Here are some ways that Boltic could potentially help in your data transformation and integration efforts:
1) Simplify the data transformation process:
Boltic's no code approach makes it easier to perform data transformation tasks without the need for coding. This can help to reduce the time and effort required to transform and integrate data.
2) Improve data quality:
Boltic's built-in data cleansing and governance features can help improve your data's quality, ensuring that it is accurate and consistent.
3) Streamline data integration:
Boltic's connectors and integrations with popular data sources and destinations make it easy to integrate data from multiple systems, streamlining the data integration process.
4) Increase efficiency:
Boltic can increase efficiency and reduce the time and effort required to complete these tasks by simplifying and automating data transformation and integration tasks.
5) Reduce the risk of errors:
Boltic's no-code approach can help to reduce the risk of errors and mistakes that can occur during data transformation and integration, as it eliminates the need for manual coding.
Boltic is a no-code data transformation tool that can help to simplify and streamline the data transformation and integration process, improve data quality, increase efficiency, and reduce the risk of errors. It is designed to be easy to use and accessible to non-technical users, making it a good option for organizations that need to transform and integrate data but do not have in-house coding expertise.
Conclusion
Apache Kafka and Apache Spark are both powerful tools for data processing, but they are designed for different types of processing. Kafka is a distributed event streaming platform used for building real-time data pipelines and streaming applications and is particularly well-suited for scenarios where data needs to be processed in near real-time. Spark is a distributed computing system used for big data processing and analytics and is particularly well-suited for scenarios where data needs to be transformed and analysed in batch mode. Both tools have built-in fault tolerance capabilities and support stream and batch processing, but Spark has more advanced analytics capabilities, including machine learning and graph processing support.
drives valuable insights
Organize your big data operations with a free forever plan
An agentic platform revolutionizing workflow management and automation through AI-driven solutions. It enables seamless tool integration, real-time decision-making, and enhanced productivity
Here’s what we do in the meeting:
- Experience Fynd Boltic's features firsthand.
- Learn how to automate your data workflows.
- Get answers to your specific questions.



