






Are you looking to upgrade your data warehousing solution and migrate from MongoDB to BigQuery?
The process may seem daunting, but it can be seamless and easy with the right approach. In this blog post, we'll walk you through the simple steps required to migrate your data from MongoDB to BigQuery.
By following these steps, you'll be able to take advantage of BigQuery's powerful scalability and analytics capabilities without any headaches. With BigQuery, you can analyse and process more extensive datasets and perform complex queries in seconds.
So if you're ready to make the switch, read on and discover how to migrate from MongoDB to BigQuery quickly and seamlessly.
Benefits of using BigQuery
Using BigQuery for data analytics and storage provides several benefits for organisations. Some of the key benefits include:

1. Scalability
BigQuery is built on top of a distributed columnar storage system and is designed to handle huge datasets with ease. It can handle billions of rows and terabytes of data with near-instant query performance. This makes it an ideal choice for organisations that must process and analyse large amounts of data.
2. Flexibility
It supports various data formats, including Avro, CSV, Parquet, and JSON, making it easy to ingest and analyse semi-structured data. This allows organisations to store and analyse data from various sources, including IoT devices, mobile applications, and weblogs.
3. Cost-effective
It is a serverless platform, meaning organisations only pay for their storage and computing resources. This eliminates the need to provision and manage expensive hardware and can help organisations save money on their data analytics infrastructure.
4. High-performance
It uses a powerful SQL engine optimised for big data analytics. This allows organisations to run complex queries and get results in seconds or even milliseconds.
BigQuery allows running parallel query execution and caching to speed up the query performance.
5. Cloud-based
It is a fully managed, cloud-based service built on top of Google's global network of data centres. This makes it easy for organisations to get started with data analytics and eliminates the need for expensive on-premises infrastructure.
6. Collaboration
BigQuery allows multiple users and teams to work on the same data simultaneously, making it easy to share insights and collaborate on projects. It also allows data access control with fine-grained access controls and provides integration with other GCP services like Data Studio, Cloud Datalab, etc.
7. Automation
It enables you to automate the data pipeline using Cloud Dataflow, Cloud Composer, and other GCP services. This eliminates the need for manual data migration and makes it easy to keep your data up-to-date and accurate.
8. Integration
It integrates with a wide range of other GCP services, including Cloud Storage, Cloud Dataproc, and Cloud Data Studio, making it easy to move data between different services and analyse it with other tools. Additionally, it also provides integration with other third-party tools.
9. Security
BigQuery provides a robust security model that includes data encryption at rest and in transit, access controls, and audit logging. It also provides integration with GCP's Identity and Access Management (IAM) service to control access to data.
10. Machine Learning
BigQuery also provides built-in support for running machine learning models using BigQuery ML. This allows you to build and train machine learning models directly within BigQuery without needing external tools or specialised expertise. It also integrates with other GCP's ML services like Tensorflow, AI Platform, etc.
Method 1: Using Boltic to set up MongoDB to BigQuery
This guide will provide a comprehensive understanding of the steps required to integrate MongoDB into Boltic.
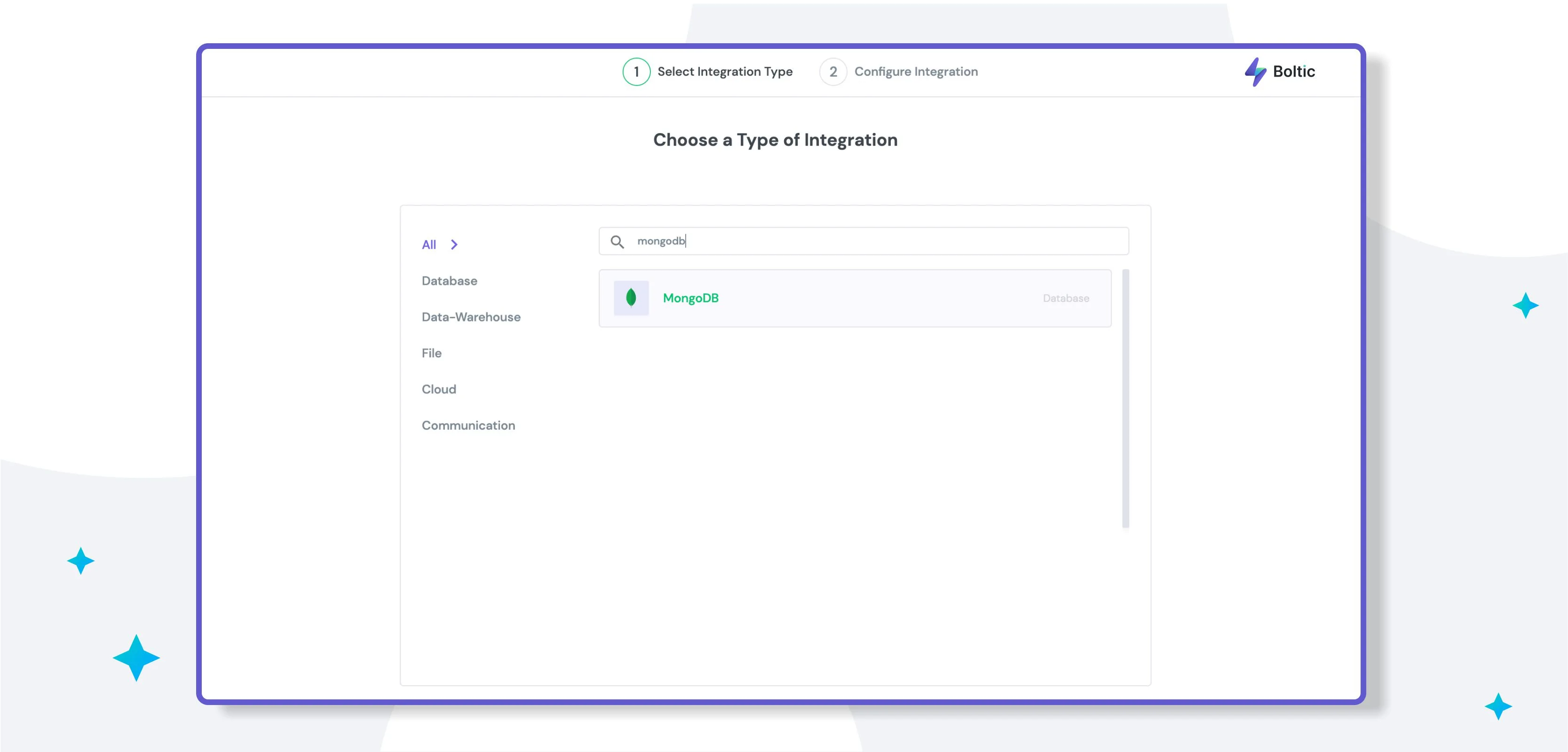
Step 1: Add Integration
Navigate to the Add Integration page and select MongoDB as the integration.
Step 2: Configuration
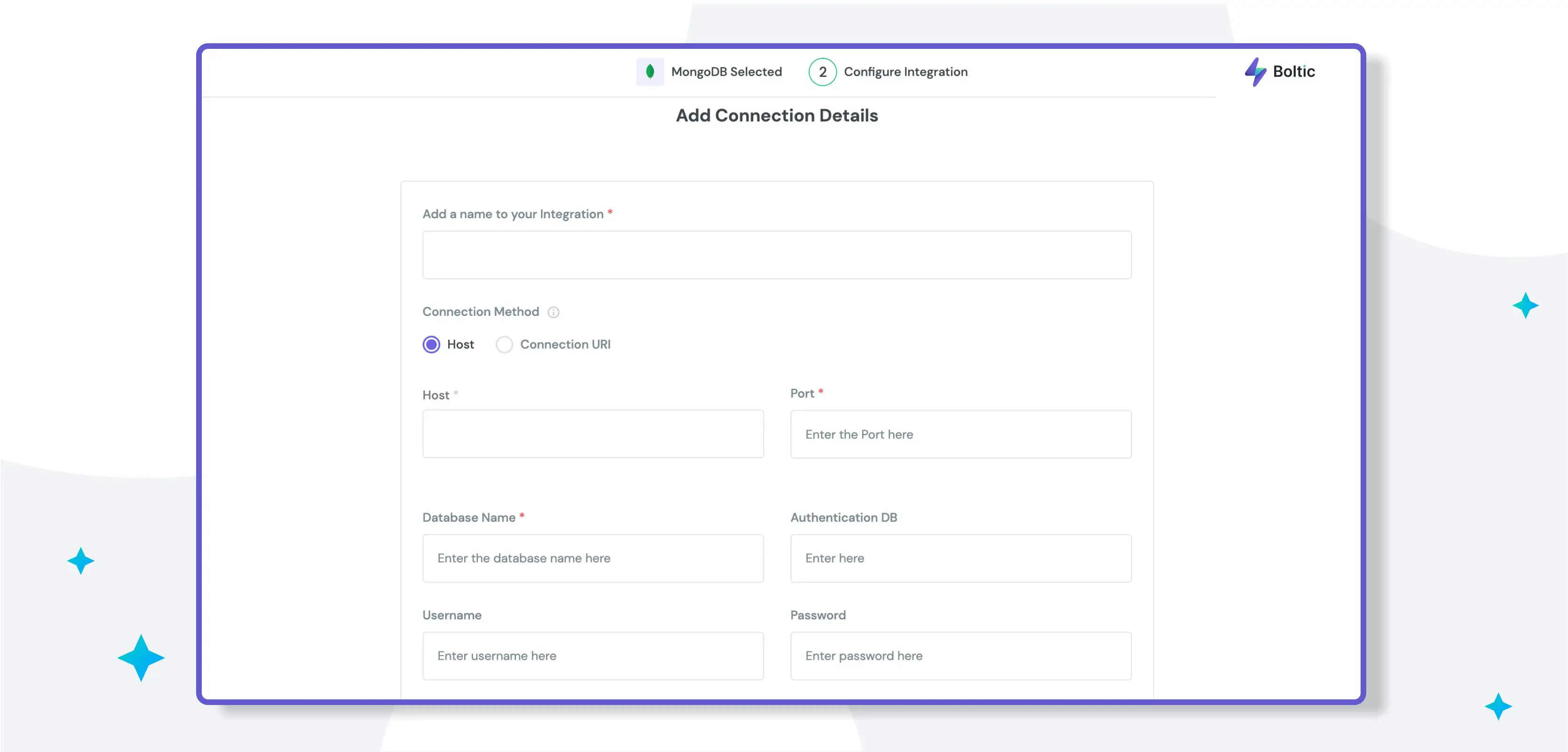
Once you have selected MongoDB as your data source, you will need to provide the following information on the Configure MongoDB Integration Page:
Connection Method: You can choose to configure the MongoDB integration using either the Host & Port Method or the Connection URI Method.
Host & Port Method:
- Host: The IP address of the MongoDB server.
- Port: The port number of the MongoDB server (default is 27018).
- Database Name: The name of the database you wish to connect to.
- Authentication DB: The authentication database you wish to use.
- Connection URI Method
- Standard Connection String: Use the prefix "MongoDB://" for this type of connection URI.
{{example1="/components"}}
Step 3: Authentication
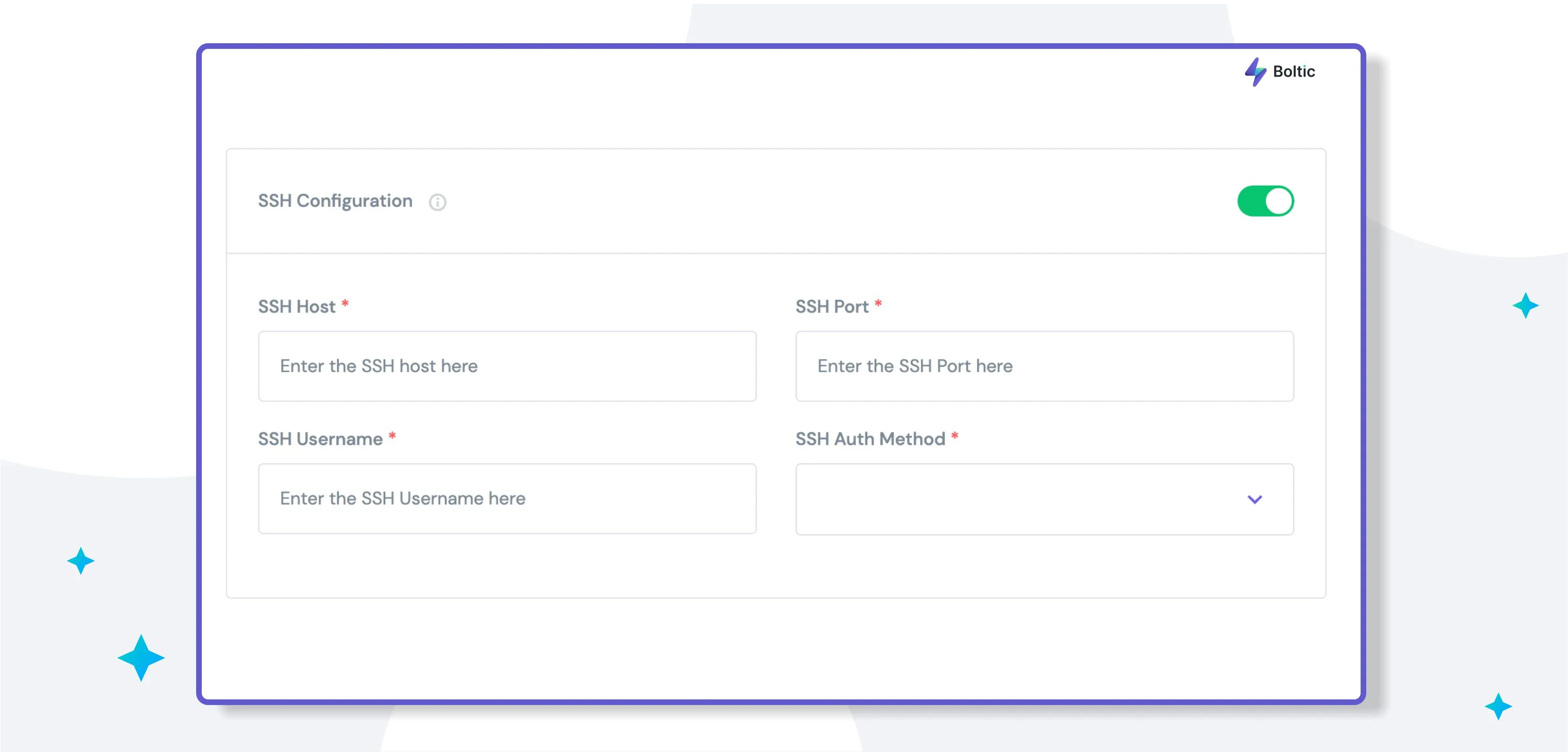
To ensure the highest level of security, you can authenticate the database using one of the following methods:
- Basic Authentication: Provide a username and password.
- SSH Authentication: Provide SSH credentials.
Note: Basic Authentication and SSH Authentication can be used together or independently.
Step 4: Test & Save
After configuring the data source, click the Test & Save button to verify that the connection is established successfully.
- Additional Information: You can add metadata, such as a description, to surface information to end-users and as tags for monitoring. Click on the More Options button to enter the metadata.
Here Are More Reasons to Try Boltic
As a no-code data transformation tool, Boltic allows users to quickly and seamlessly process, clean, and transform large datasets without needing to write any code. Here are a few additional reasons why you might want to try Boltic:

1. User-friendly interface
Boltic's user interface is designed to be easy to use, with a drag-and-drop interface and simple controls for data transformation. Users can quickly start processing and transforming their data without learning a programming language.
2. Increased efficiency
With Boltic, users can automate repetitive tasks such as data cleaning, validation, and transformation. This can significantly speed up the data transformation process and save users significant time and effort.
Additionally, it has a user-friendly interface that allows users to manage multiple datasets and perform various transformations in one go, a time saver.
3. Flexibility
It supports various data sources, including CSV, Excel, JSON, and more, which means users can work with the data they have, no matter where it comes from. This also enables users to connect to different data sources and perform the transformation on data that resides in various platforms like MongoDB, Bigquery, etc.
4. Scalability
It can handle large data sets and perform complex operations on them. The tool uses parallel processing to handle the data at high performance and thus can handle large datasets.
5. Advanced analytics and visualization
It enables users to perform advanced analytics on their data, such as aggregation, sorting, and filtering. Additionally, it provides data visualization options, which help users to understand their data and make better-informed decisions easily.
6. Cost-effective
It is a cost-effective option for businesses, as it allows business users, data analysts, and data scientists to perform data transformation tasks without requiring developer assistance.
This can result in significant cost savings compared to other alternatives and enables teams to self-serve their data needs without needing a developer's help.
7. Advanced data cleaning
It provides a wide range of data cleaning options, including data validation, duplicate removal, and data standardization, doing cleaning and preparing data for analysis and decision-making easier.
8. Real-time data processing
It can process data in real-time, which makes it an excellent tool for applications that require up-to-date data and real-time decision-making. This is particularly useful for organisations that deal with large amounts of data and need to process it as soon as it is generated.
9. Robust data mapping:
Its data mapping feature allows users to map fields from different data sources to each other, which makes it easy to integrate data from multiple sources and ensure data consistency and accuracy.
10. Reusable data pipelines
With Boltic, users can create reusable data pipelines, which can be applied to new data sets with minimal effort. This enables the creation of a set of steps for data transformation once and uses it for multiple datasets. This saves time and effort and also ensures consistency across different datasets.
Boltic is a powerful and user-friendly data transformation tool that can help businesses and organisations efficiently process, clean, and transform their data without coding knowledge.
It can also be used to perform advanced analytics and data visualisation, which can provide valuable insights and help users make better-informed decisions.
Method 2: Manual Steps to Stream Data from MongoDB to BigQuery
A step-by-step process for linking MongoDB to BigQuery and streaming your data manually:
Step 1: Extract Data from MongoDB
The initial step in streaming your data from MongoDB to BigQuery is to extract the data. To do this, you can utilise the "mongoexport" utility. This tool can be utilised to produce a JSON or CSV export of the data stored in a MongoDB collection.
To use mangoexport to stream data from MongoDB to BigQuery, here are a few guidelines to keep in mind:
- mongoexport must be run directly from the system command line and not from the Mongo Shell.
- Ensure that the connecting user has at least the read role on the target database.
- mongoexport defaults to primary read preference when connected to Mongo or a replica set.
- The default read preference can be overridden using the "--readPreference" option.
An example of exporting data from the "cont_collect" collection to a CSV file located at "/opt/exports/csv/cnts.csv" would be:
{{example2="/components"}}
Note that when exporting in CSV format, you must specify the fields in the documents to export. In the above example, we specified the "contact_name" and "contact_address" fields to export. The output would look like this:
{{example3="/components"}}
Then, using the "--fieldFile" option, you can define the fields to export with the file:
{{example2="/components"}}
By default, field names are included as a header. The "--noHeaderLine" option can eliminate the field names in a CSV export.
Incremental Data Extract from MongoDB
Instead of extracting the entire collection, you can pass a query and filter data. This option can be used to extract data incrementally. The "--query" or "-q" option is used to pass this option.
For example, let's consider the "contacts" collection discussed above. Suppose the "last_updated_time" field in each document stores the last updated/inserted Unix Timestamp for that document.
The following command will extract all records from the collection that have a "last_updated_time" greater than the specified value, 1548930176:
{{example4="/components"}}
It is essential to keep track of the last pulled "last_updated_time" separately.
Step 2: Optional Clean and Transform Data
The second step in migrating data from MongoDB to BigQuery can be the most complex, as it involves transforming the data to meet BigQuery's requirements.
In addition to any transformations required to meet your business logic, there are a few basic things to keep in mind while preparing data from MongoDB to BigQuery.
- BigQuery expects UTF-8 encoded CSV data. If the data is encoded in ISO-8859-1 (Latin-1), you must explicitly specify this while loading the data into BigQuery.
- BigQuery doesn't enforce Primary Key and Unique Key constraints. The ETL (Extract, Transform, and Load) process must take care of these.
- Column types are different between MongoDB and BigQuery. Most types have equivalent or convertible types. Here is a list of common data types and their equivalents:
{{MongoDBData="/components"}}
- DATE values must be in the form of YYYY-MM-DD (Year-Month-Day) and separated by dashes (-). Fortunately, the mongoexport date format is already in this format, so no modification is required to connect MongoDB to BigQuery.
- Please quote text columns if they can potentially contain Delimiter Characters.
Step 3: Upload to Google Cloud Storage (GCS)
After extracting the data from MongoDB, the next step is to upload it to GCS. There are various ways to do this.
Gsutil is the standard Google Cloud Platform (GCP) tool to handle Objects and Buckets in GCS. It has options to upload a file from your local machine to GCS.
{{example5="/components"}}
Storage Transfer Service from Google Cloud is an alternative option for uploading files to GCS from S3 or other online data sources, provided the destination is a Cloud Storage Bucket.
This service supports GCS Bucket as a source. It is helpful for data movement to GCS with options such as
- Both first-time and recurring loads can be scheduled.
- After successfully transferring data to GCS, the source data can be deleted.
- Periodic synchronisation between source and target can be selected using filters.
Uploading From The Web Console:
Step 1. Login to GCP, click on "Storage," and go to "Browser" in the left bar.
Step 2. Select the GCS Bucket with the proper access where you want to upload the file that will be loaded to BigQuery.
Step 3. Click on the "Bucket Name" to go to the Bucket details page.
Step 4. Click on "Upload Files" and select the file from your computer.
Step 5. Wait for the upload to complete, and the file will be listed in the Bucket.
Step 6. Please note that the example above contains some special characters that may not be displayed correctly on some devices, but the commands should work correctly.
Step 4: Upload Data Extracted from MongoDB to BigQuery Table from GCS
Once the data is uploaded to GCS, you can use the Web Console UI or the Command Line tool bq to stream the data from MongoDB to a BigQuery Table.
Using the Web Console:
- Go to the BigQuery Console from the left side panel.
- Create a dataset if not present already.
- Click on the created datasets on the left side, and the "Create Table" option will appear below the Query Editor.
- The "Create Table" button will open a wizard with options to specify the table's input source and other specifications.
- You can specify the schema or use the auto-detect option.
Using the Command Line tool bq:
The bq load command can upload data from MongoDB to BigQuery using GCS and the source_format CSV.
The syntax of the bq load command is as follows:
{{example6="/components"}}
- You can also use the --autodetect flag instead of supplying a schema definition.
There are additional options specific to CSV data load:
{{csvp="/components"}}
{{example7="/components"}}
A new schema JSON file with the extra field can be given as an option to add a new field to the target table.
Step 5: Update Target Table in BigQuery
This step is the final step in streaming data from MongoDB to BigQuery. To update the target table with new data, you can initially load the data into a Staging Table as a full load. This table can be referred to as an intermediate delta table.
There are two approaches to loading data to the final table:
Update the rows in the final table and insert new rows from the delta table which are missing from the final table using the following code:
{{example8="/components"}}
Delete rows from the final table which are in the delta table, and then insert all records from the delta table to the final table using the following code:
{{example9="/components"}}
Both of these approaches will update the final table with new data from the delta table. The first approach updates existing rows and inserts new ones, while the second approach deletes any rows in the delta table and then inserts all records from the delta table.
It is important to note that before using these queries, it is recommended to take a backup of the final table and test the queries on a small subset of data to ensure that they work as expected.
Considerations for Migrating from MongoDB to Big Query

1. Data Modeling
Data modelling is one of the key considerations when migrating from MongoDB to BigQuery. MongoDB is a document-based NoSQL database, while BigQuery is a columnar, SQL-based data warehouse.
The data structure and schema will need to be adapted to fit the new system. It's essential to understand the data model and structure of the MongoDB data and how it can be translated into a BigQuery schema.
2. Cost Constraints
Another consideration is cost. BigQuery is a fully managed service, so organisations only pay for the storage and computing resources they use.
However, it's essential to consider the cost of data storage and processing, especially for large datasets. Organisations should also consider the cost of migrating the data and the cost of any additional tools or services that might be needed.
3. Querying
MongoDB and BigQuery use different query languages. MongoDB uses MongoDB Query Language (MQL), while BigQuery uses SQL. This means that organizations must update and test their existing queries and any scripts or applications that use the data to ensure they work with the new system.
It's essential to evaluate the complexity of the existing queries and any performance issues that might arise from migrating them to BigQuery.
4. Security
Security is another crucial consideration when migrating from MongoDB to BigQuery. BigQuery provides a robust security model that includes data encryption at rest and in transit, access controls, and audit logging.
Organizations should evaluate the security needs of their data and ensure that the data is protected during the migration process and that the new system meets its security requirements.
It's important to consider compliance and regulatory requirements and evaluate the security features of MongoDB and BigQuery to ensure that they meet the organization's specific needs.
Post-migration
Post-migration, there are several key considerations to keep in mind to ensure that the migration from MongoDB to BigQuery is successful and that the new system meets the organization's needs. Some of these considerations include
1. Performance Testing.
After migrating from MongoDB to BigQuery, it's essential to perform performance testing to ensure that the new system meets the organization's requirements.
This can include testing query performance, data load performance, and overall system performance. This will help identify any issues that need to be addressed, such as slow queries or data load bottlenecks, and ensure that the new system can handle the expected workload.
2. Troubleshooting
Migrating to a new system can introduce new challenges, and organizations should be prepared to troubleshoot any issues. This can include issues with data quality, data consistency, or performance.
It's essential to have a plan in place for troubleshooting and resolving issues and the necessary tools and resources to address any problems that arise.
3. Security and Access Control
Security and access control are critical for protecting sensitive data, and organizations should ensure their data is secure after migrating to BigQuery.
This can include configuring access controls, setting up encryption for data at rest and in transit, and monitoring suspicious activity. Organizations should also review and update their security policies and procedures and ensure that all users have the necessary permissions to access the data they need.
4. Data Backup and Recovery
After migrating to BigQuery, organizations should implement a data backup and recovery strategy to protect their data in an emergency or disaster. This can include creating regular backups of the data and storing them securely.
Organizations should also test their backup and recovery procedures to ensure that they can quickly and easily restore the data in case of an emergency.
5. Scalability
As data grows, organizations should ensure that their system can handle the increased volume and complexity. BigQuery is built for high scalability, but it's essential to regularly monitor the data storage, query performance, and data pipeline to ensure that the system can handle the increasing data volume.
Organizations should also consider data archiving and partitioning strategies to optimize performance and reduce costs as the data grows.
Conclusion
Migrating from MongoDB to Big Query is a simple and seamless process that can be accomplished by following a few easy steps. With the help of the right tools and services, you can easily and quickly migrate your data from MongoDB to Big Query and take advantage of its powerful features and flexibility.
With Big Query, you can improve your data management and analytics, allowing your organization to make better decisions and grow quickly.
You can also use Boltic for a seamless and quick migration.
drives valuable insights
Organize your big data operations with a free forever plan
An agentic platform revolutionizing workflow management and automation through AI-driven solutions. It enables seamless tool integration, real-time decision-making, and enhanced productivity
Here’s what we do in the meeting:
- Experience Fynd Boltic's features firsthand.
- Learn how to automate your data workflows.
- Get answers to your specific questions.



