Import Libraries
Languages like JavaScript and Python are the ways to accomplish data transformation goals. We don't let our users to spend more time on writing scripts than understanding the data. Boltic' Script Engine supports preloaded libraries and packages for both JavaScript and Python languages to facilitate data transformation. These are sets of pre-written functions and statements that can be used to extend the capabilities of the languages and make data transformation by writing scripts convenient and easier.
Java Script Import Libraries
| Package | Description | Version |
|---|---|---|
| Lodash | Lodash simplifies JavaScript by removing the hassle of dealing with arrays, numbers, objects, texts, and other data types. | 4.17.21 |
| Moment | A date library for JavaScript that parses, validates, manipulates, and formats dates. | 2.29.3 |
The Script Engine supports library import using Node JS syntax () Supported syntax are as follows-
// Load the full build.
var _ = require('lodash');
// Load the core build.
var _ = require('lodash/core');
// Load the FP build for immutable auto-curried iteratee-first data-last methods.
var fp = require('lodash/fp');
// Load method categories.
var array = require('lodash/array');
var object = require('lodash/fp/object');
// Cherry-pick methods for smaller browserify/rollup/webpack bundles.
var at = require('lodash/at');
var curryN = require('lodash/fp/curryN');
Example 1: Aggregation Using Lodash
In Javascript language, making the sum method might not be complicated. However, if our Script Engine supports the Lodash package, that will make you write aggregate more easily.
In the following example, we have imported the Lodash library to get the total sum of the columns Total Revenue and Units Sold, a total count of Order_ID and group by Sales Channel.
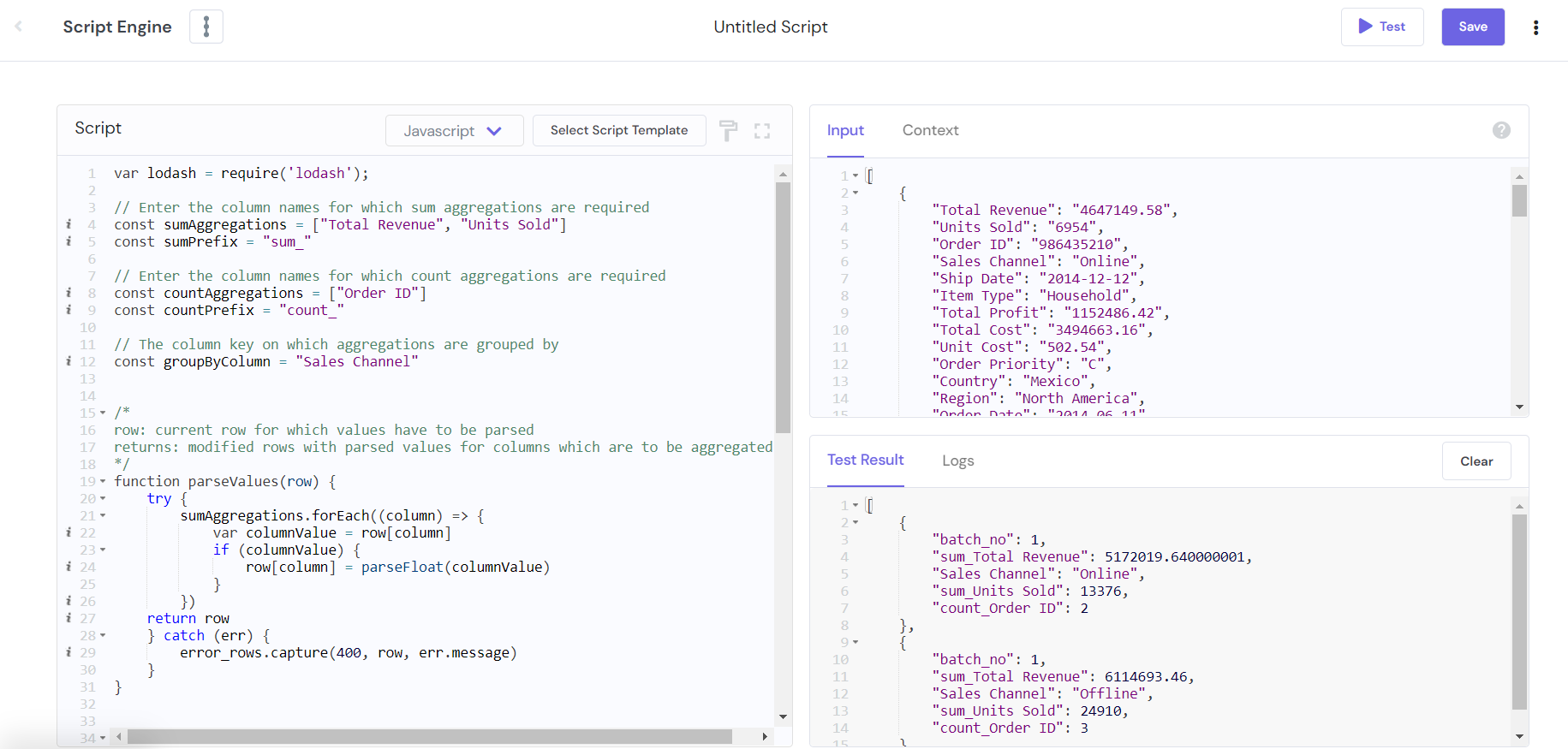
var lodash = require('lodash');
// Enter the column names for which sum aggregations are required
const sumAggregations = ["Total Revenue", "Units Sold"]
const sumPrefix = "sum_"
// Enter the column names for which count aggregations are required
const countAggregations = ["Order ID"]
const countPrefix = "count_"
// The column key on which aggregations are grouped by
const groupByColumn = "Sales Channel"
/*
row: current row for which values have to be parsed
returns: modified rows with parsed values for columns which are to be aggregated
*/
function parseValues(row) {
try {
sumAggregations.forEach((column) => {
var columnValue = row[column]
if (columnValue) {
row[column] = parseFloat(columnValue)
}
})
return row
} catch (err) {
error_rows.capture(400, row, err.message)
}
}
/*
rows: rows grouped by the given key
key: the key on which aggregation is grouped by
context: context information for the pipeline batch
returns: row containing aggregations for the given key
*/
function aggregateRows(rows, key, context) {
var aggregatedRow = {}
aggregatedRow[groupByColumn] = key
sumAggregations.forEach((column) => {
aggregatedRow[sumPrefix + column] = lodash.sumBy(rows, column)
})
countAggregations.forEach((column) => {
aggregatedRow[countPrefix + column] = lodash.uniqBy(rows, column).length
})
aggregatedRow["batch_no"] = context.getBatchNo()
return aggregatedRow
}
/*
rows: batch data being processed in the pipeline
context: context information for the pipeline batch
returns: modified rows of the pipeline batch data
*/
function process(rows, context) {
var results = lodash(rows)
.map(row => parseValues(row))
.groupBy(groupByColumn)
.map((rows, key) => aggregateRows(rows, key, context))
.value()
return results
}
Example 2: Process Time Using Moment
The Moment is a JavaScript library that allows users to parse, validate, and manipulate dates and times.
In the second example, we have imported the Moment library to get the current time and date.
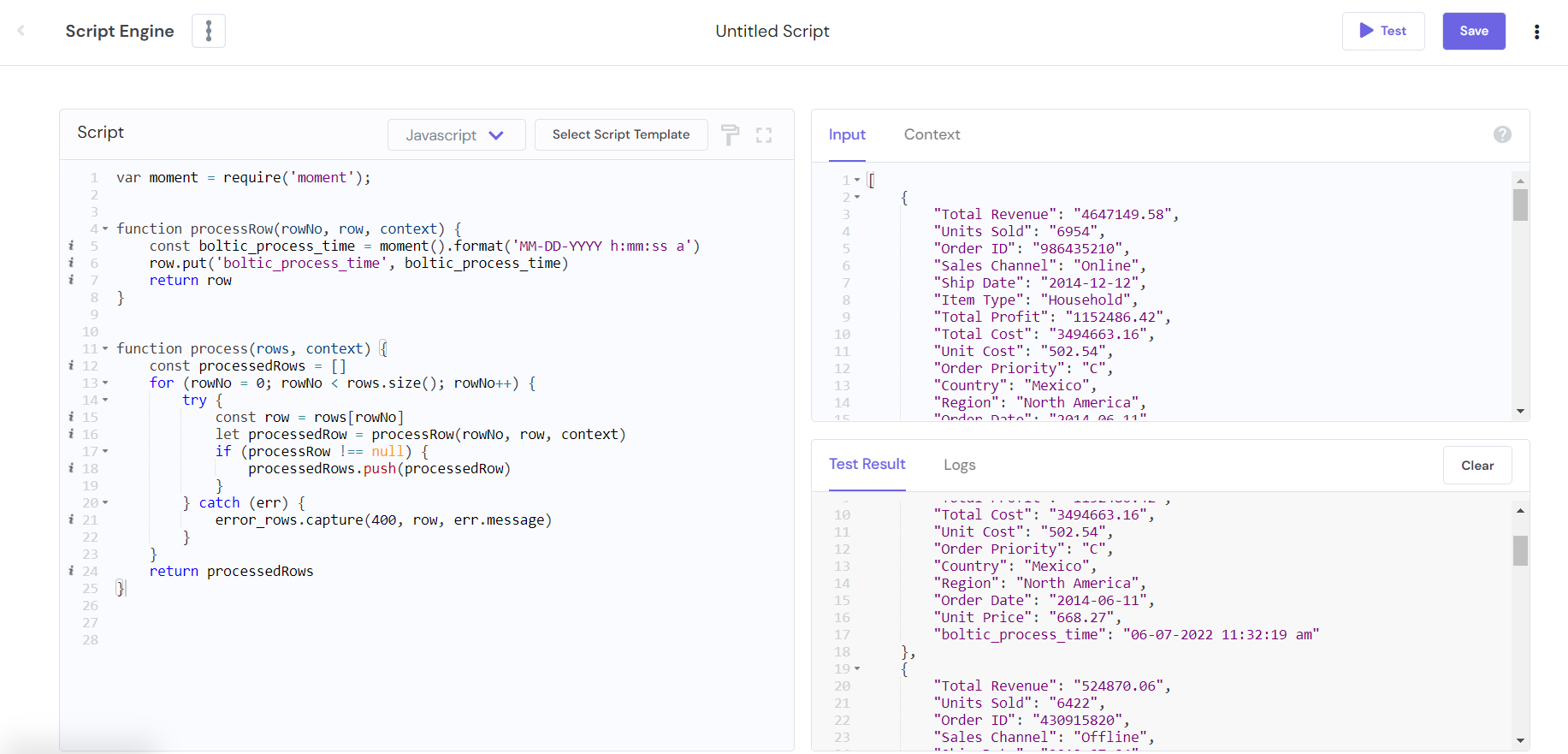
var moment = require('moment');
function processRow(rowNo, row, context) {
const boltic_process_time = moment().format('MM-DD-YYYY h:mm:ss a')
row.put('boltic_process_time', boltic_process_time)
return row
}
function process(rows, context) {
const processedRows = []
for (rowNo = 0; rowNo < rows.size(); rowNo++) {
try {
const row = rows[rowNo]
let processedRow = processRow(rowNo, row, context)
if (processRow !== null) {
processedRows.push(processedRow)
}
} catch (err) {
error_rows.capture(400, row, err.message)
}
}
return processedRows
}
Unsupported modules
async- await
The following will give unexpected results:
async function process(rows, context) {
// Write your code here
return rows
}
async function processRow(rowNo, row, context) {
// Write your code here
let processPromise = new Promise(function(resolve) {
setTimeout(function() {resolve(moment.format('MM-DD-YYYY h:mm:ss a'));}, 3000);
});
let processTime = await processPromise
row.put('boltic_process_time', processTime)
return row
}
function process(rows, context) {
const processedRows = []
for (rowNo = 0; rowNo < rows.size(); rowNo++) {
try {
const row = rows[rowNo]
let processedRow = processRow(rowNo, row, context)
if (processRow !== null) {
processedRows.push(processedRow)
}
} catch (err) {
error_rows.capture(400, row, err.message)
}
}
return processedRows
}
Python Import Libraries
In Python, a library is a collection of modules that may be used repeatedly in different scripts without having to write them from scratch.
How to import module in Python?
# import module_name import datetime script.log(datetime.datetime.now())
# import module_name.member_name from datetime import datetime script.log(datetime.now())
Examples
Aggregations using itertools
from itertools import groupby
# Enter the column names for which sum aggregations are required
sum_aggregations = ["Total Revenue", "Units Sold"]
# Enter the column names for which count aggregations are required
count_aggregations = ["Order ID"]
# The column key on which aggregations are grouped by
group_by_column = "Sales Channel"
key_function = lambda row: row[group_by_column]
"""
row: current row for which values have to be parsed
returns: modified rows with parsed values for columns which are to be aggregated
"""
def parse_values(row):
try:
for column in sum_aggregations:
if column in row:
parsed_value = float(row[column])
row[column] = parsed_value
return row
except Exception as e:
error_rows.capture(400, row, str(e))
"""
rows: rows grouped by the given key
key: the key on which aggregation is grouped by
context: context information for the pipeline batch
returns: row containing aggregations for the given key
"""
def aggregate_rows(rows, key, context):
aggregated_row = {}
aggregated_row[group_by_column] = key
for column in sum_aggregations:
sum_value = sum(row[column] for row in rows)
aggregated_row[column] = sum_value
for column in count_aggregations:
count_value = len(set(row[column] for row in rows))
aggregated_row[column + " Count"] = count_value
return aggregated_row
"""
rows: batch data being processed in the pipeline
context: context information for the pipeline batch
returns: modified rows of the pipeline batch data
"""
def process(rows, context):
aggregated_rows = []
sorted_rows = sorted(rows, key=key_function)
for key, grouped_rows in groupby(sorted_rows, key=key_function):
grouped_rows = map(parse_values, list(grouped_rows))
aggregated_row = aggregate_rows(list(grouped_rows), key, context)
aggregated_rows.append(aggregated_row)
return aggregated_rows
Output:
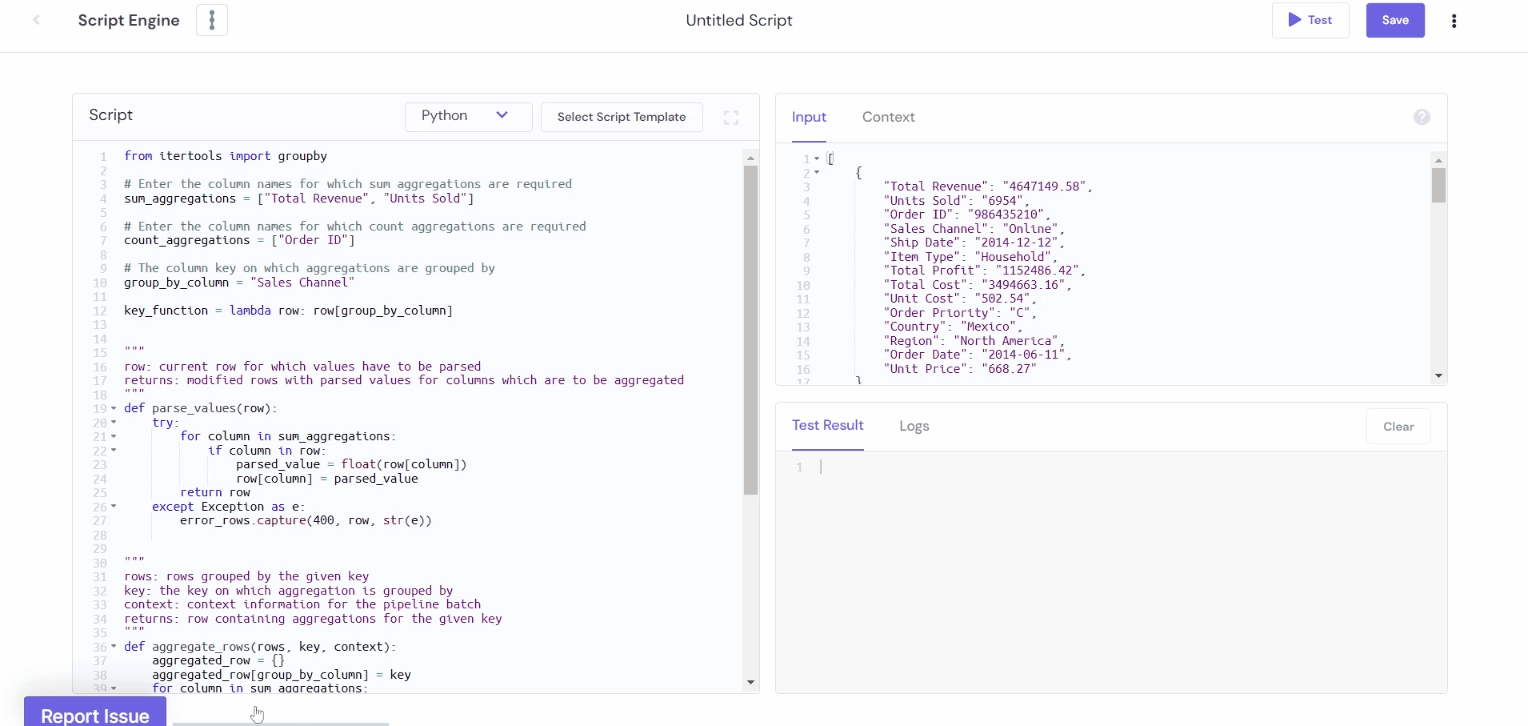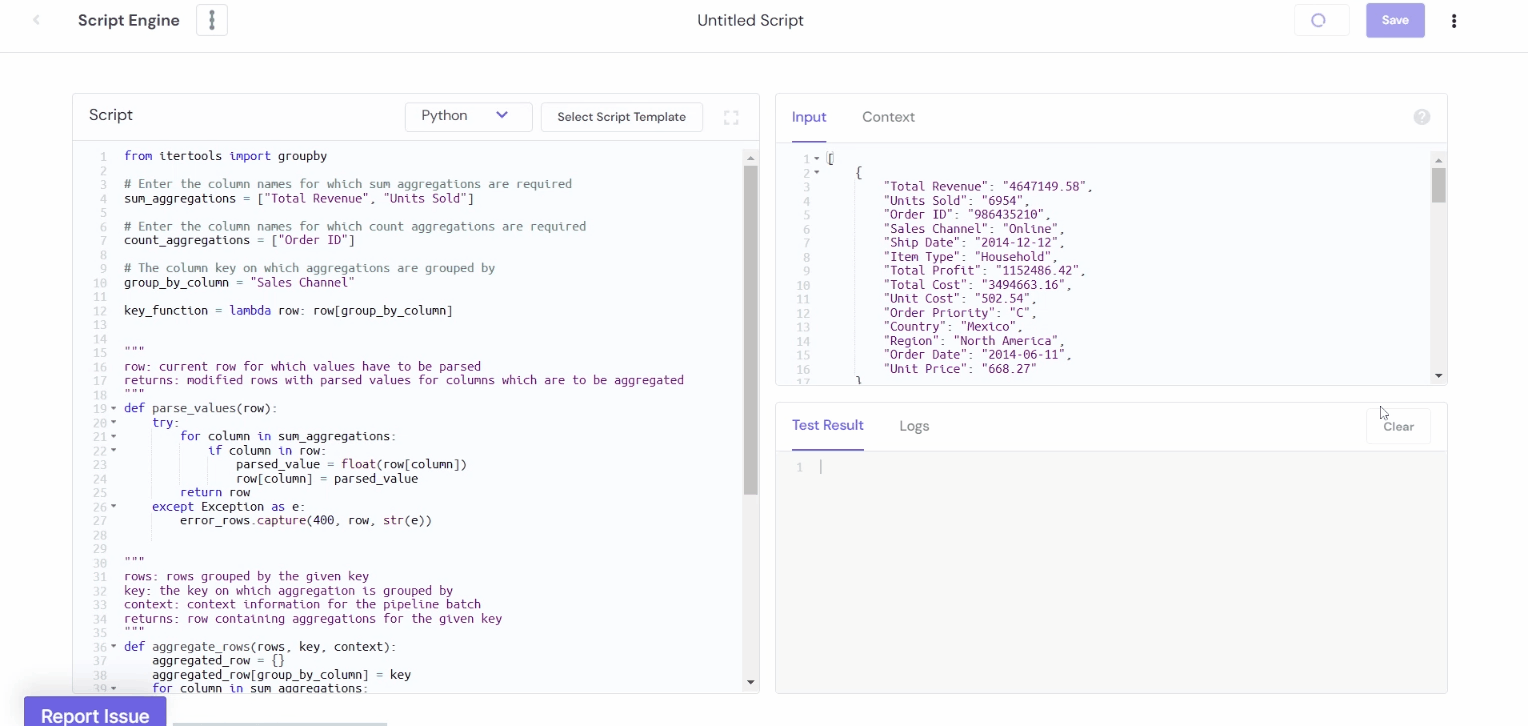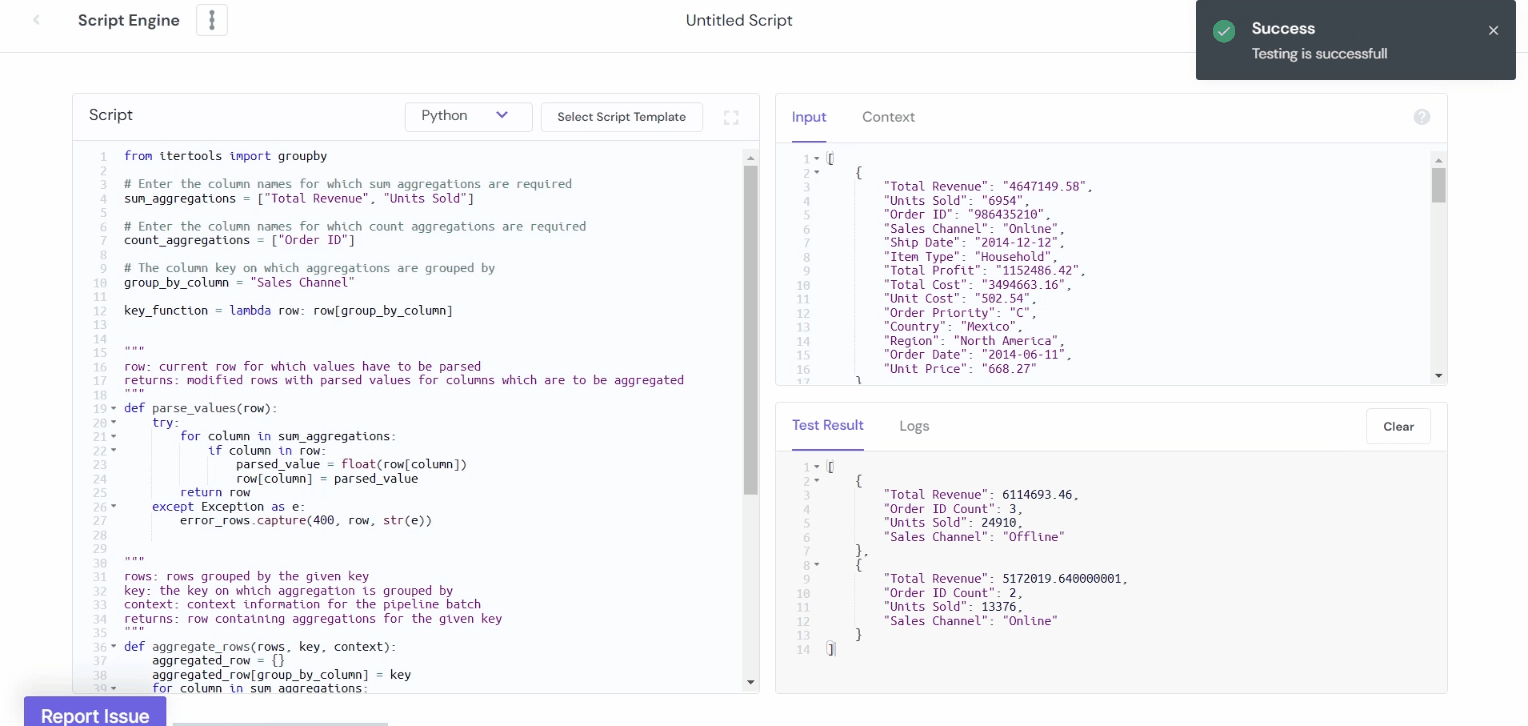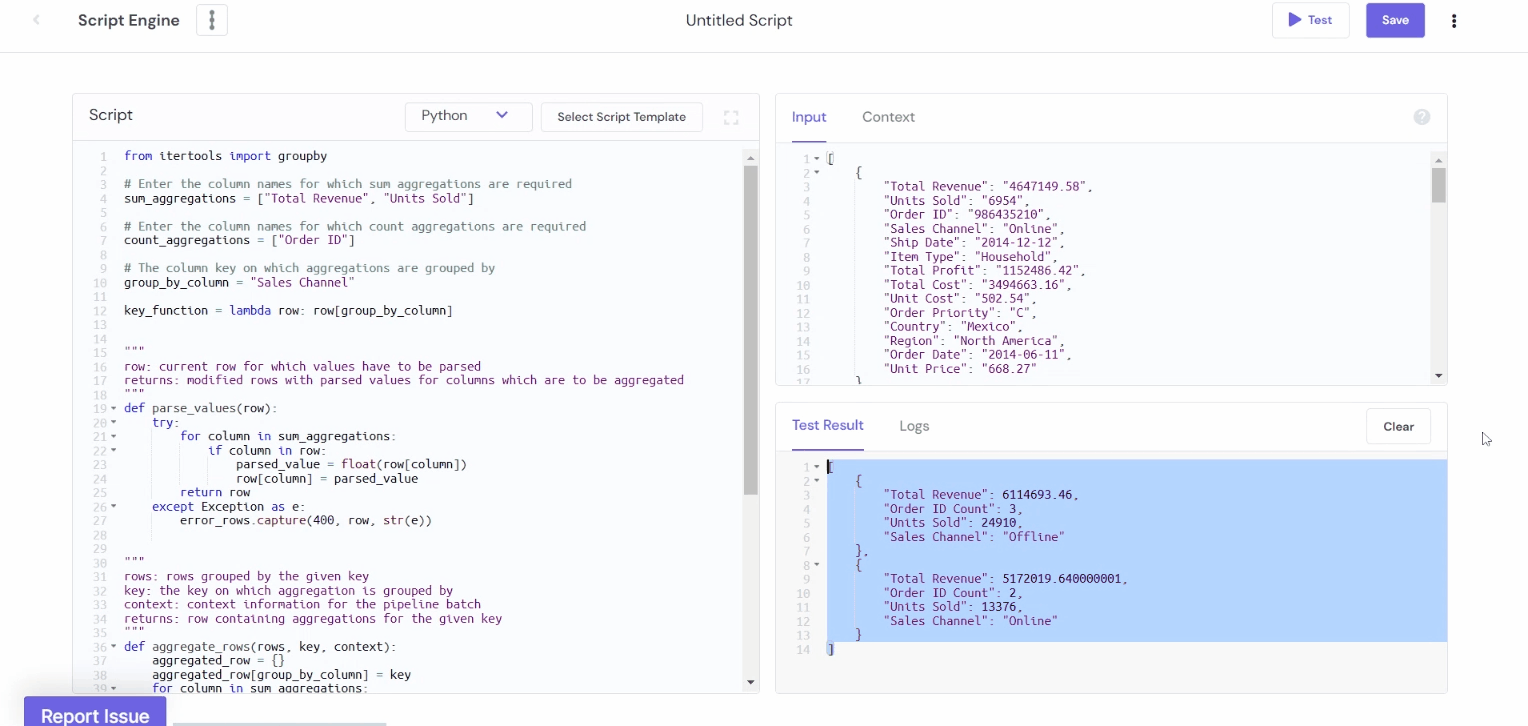
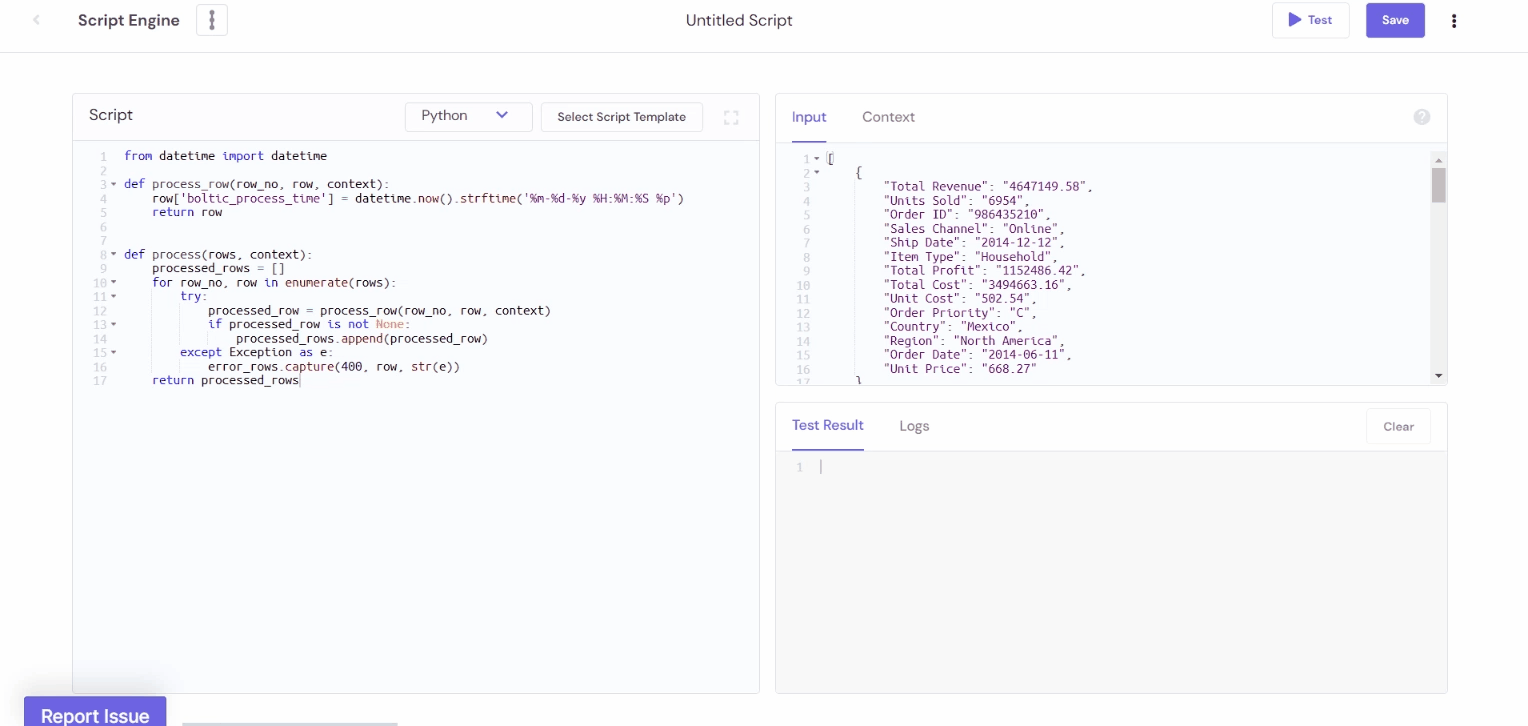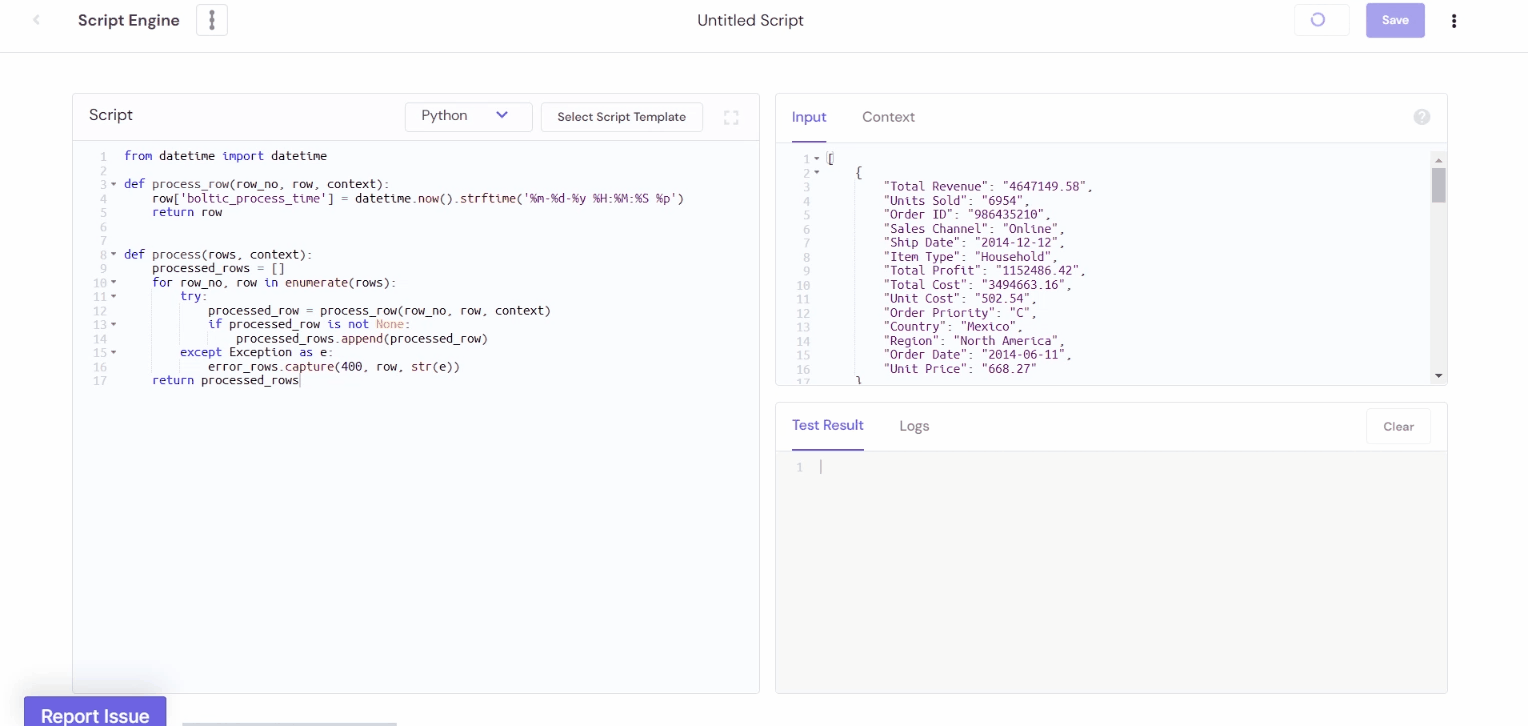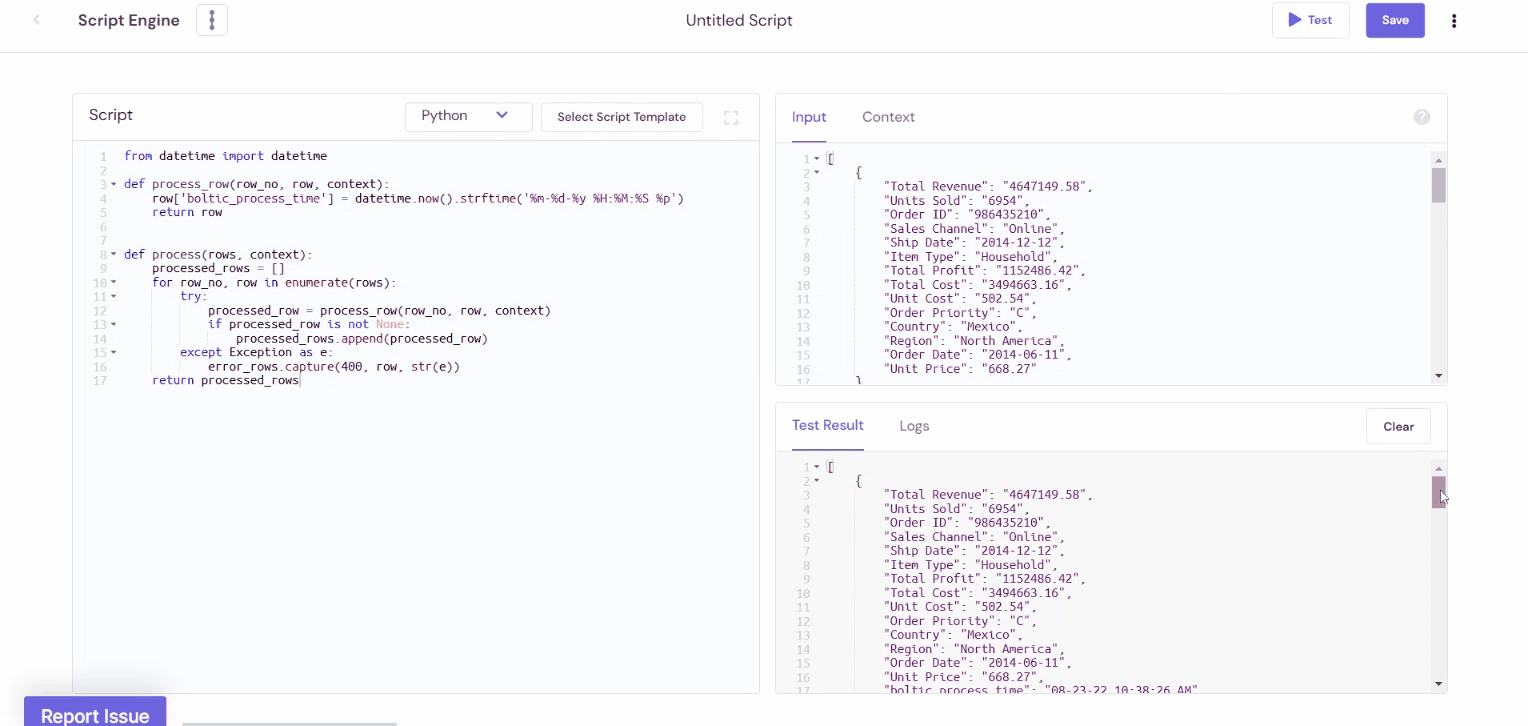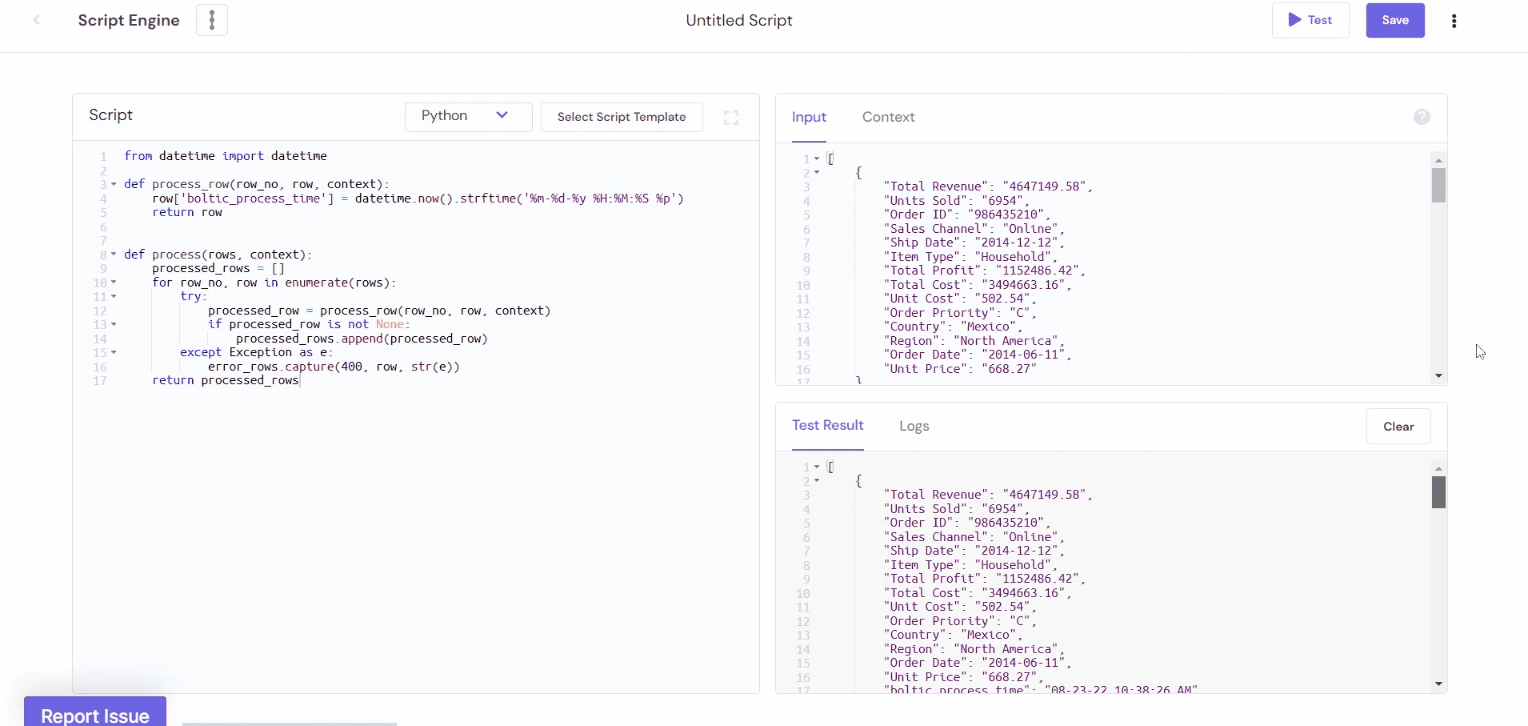
Process time using datetime
from datetime import datetime
def process_row(row_no, row, context):
row['boltic_process_time'] = datetime.now().strftime('%m-%d-%y %H:%M:%S %p')
return row
def process(rows, context):
processed_rows = []
for row_no, row in enumerate(rows):
try:
processed_row = process_row(row_no, row, context)
if processed_row is not None:
processed_rows.append(processed_row)
except Exception as e:
error_rows.capture(400, row, str(e))
return processed_rows
Output:
Any Question? 🤓
We are always an email away to help you resolve your queries. If you need any help, write to us at - 📧 support@boltic.io