Custom Script Examples
These custom script examples provide information about the contents of the custom script.
Example 1: Sanitizing the Column Names
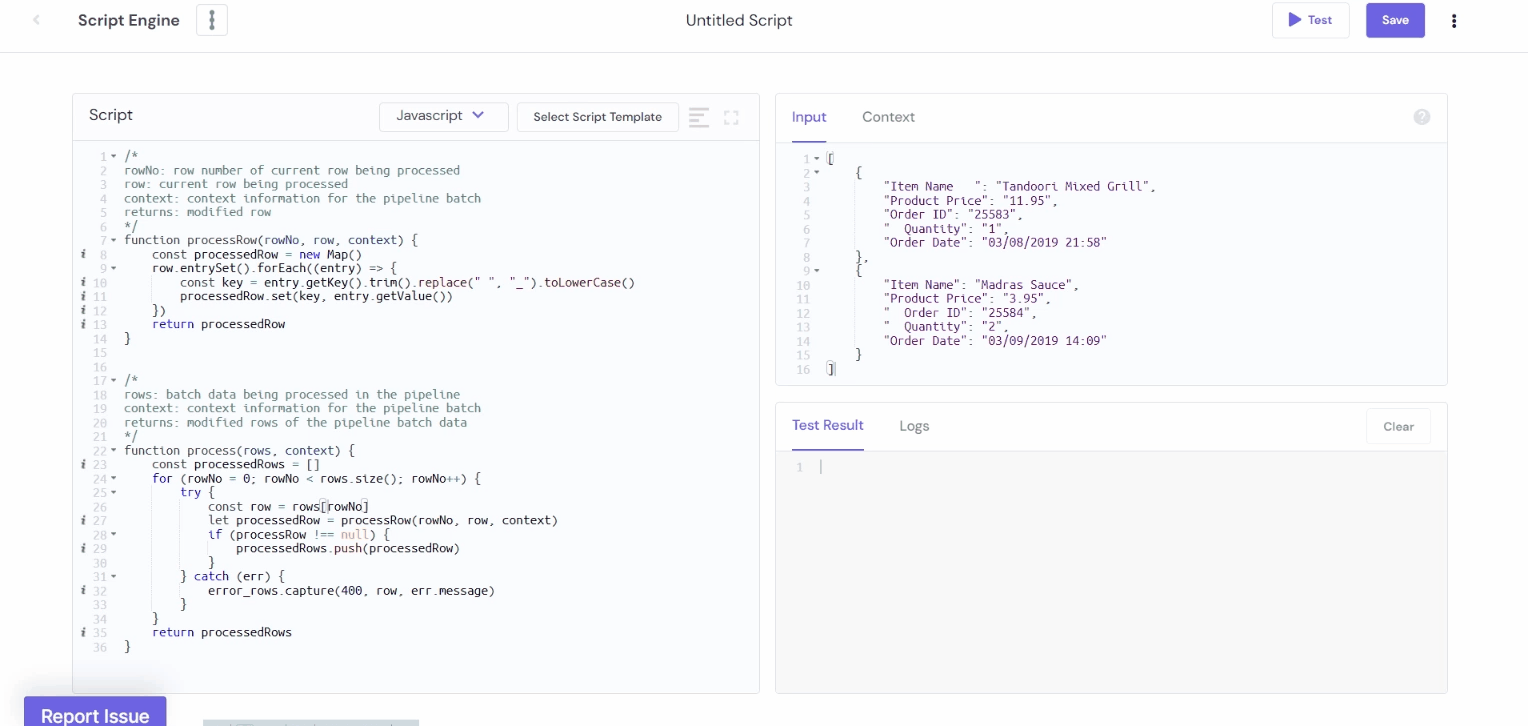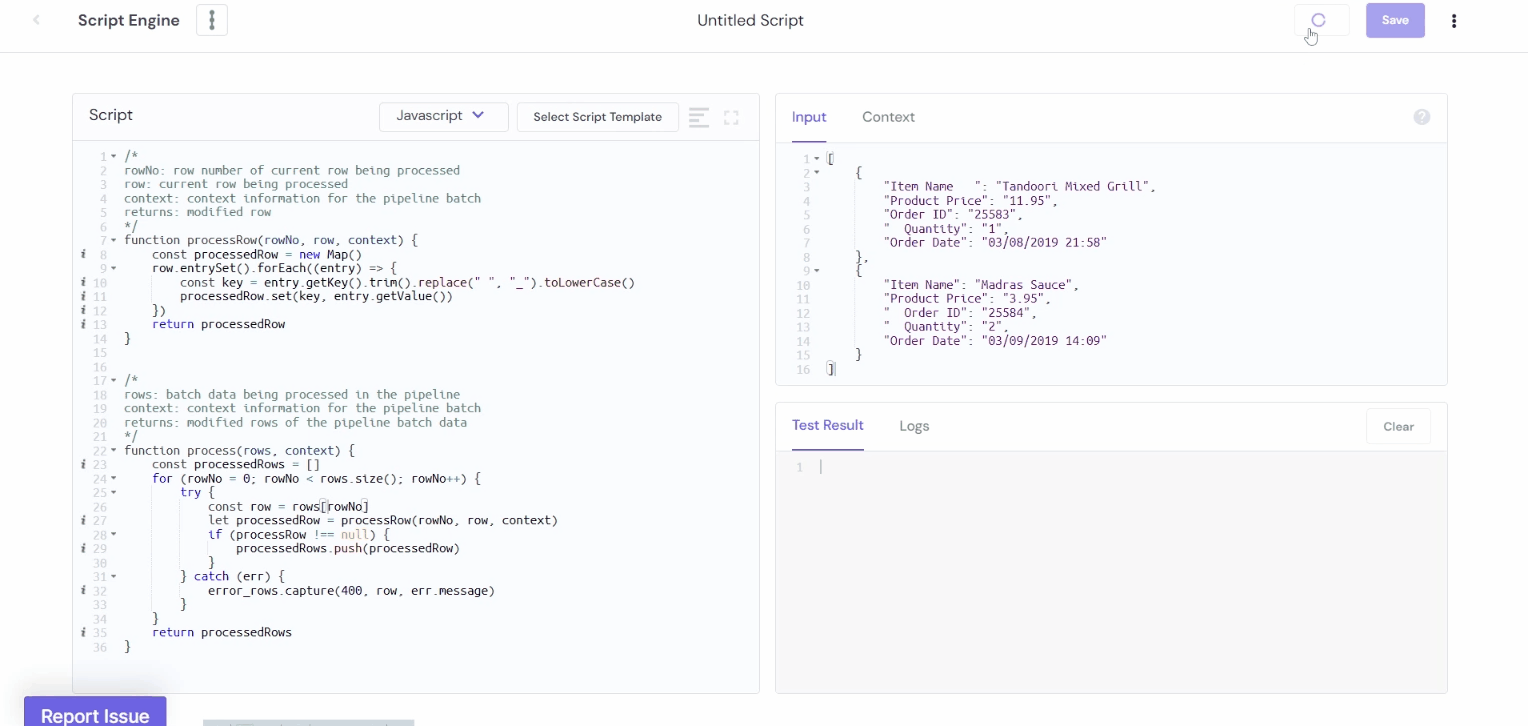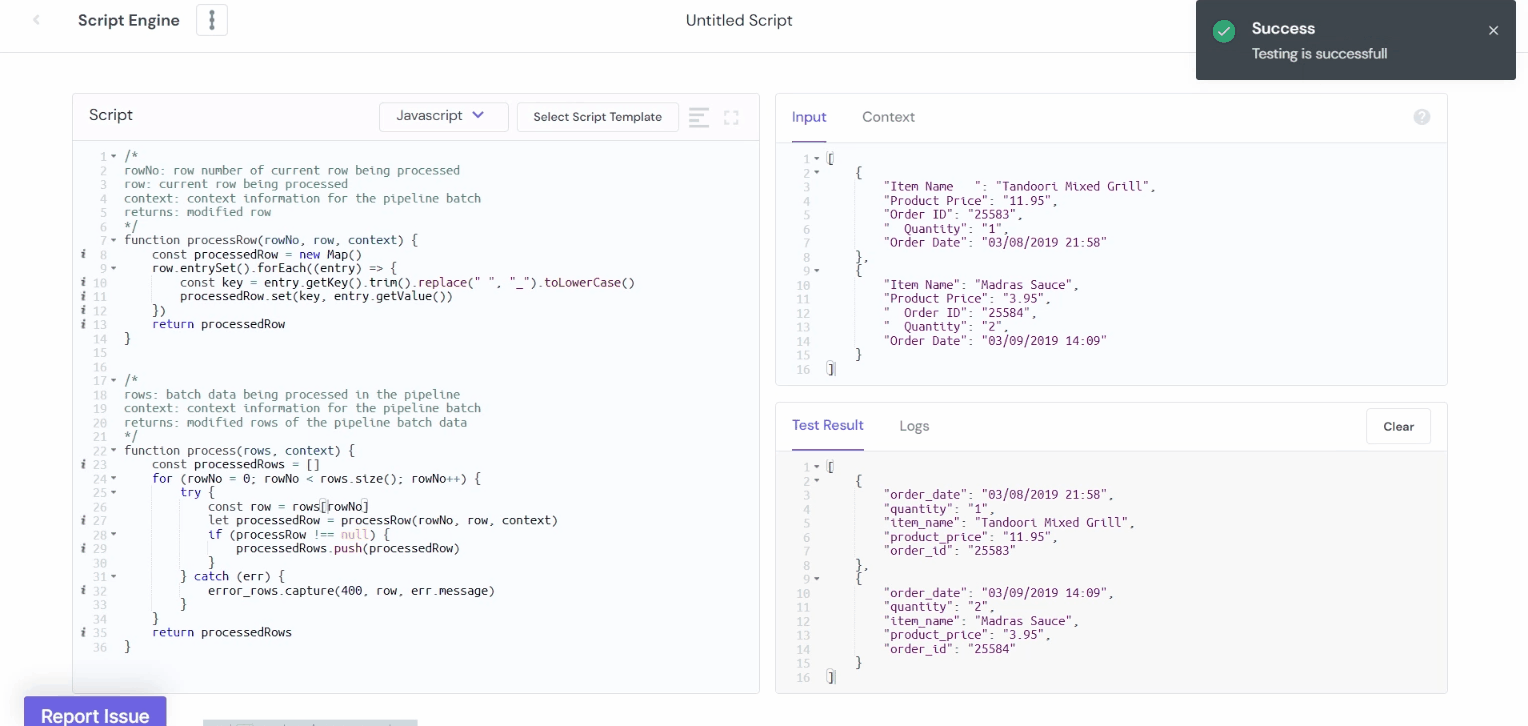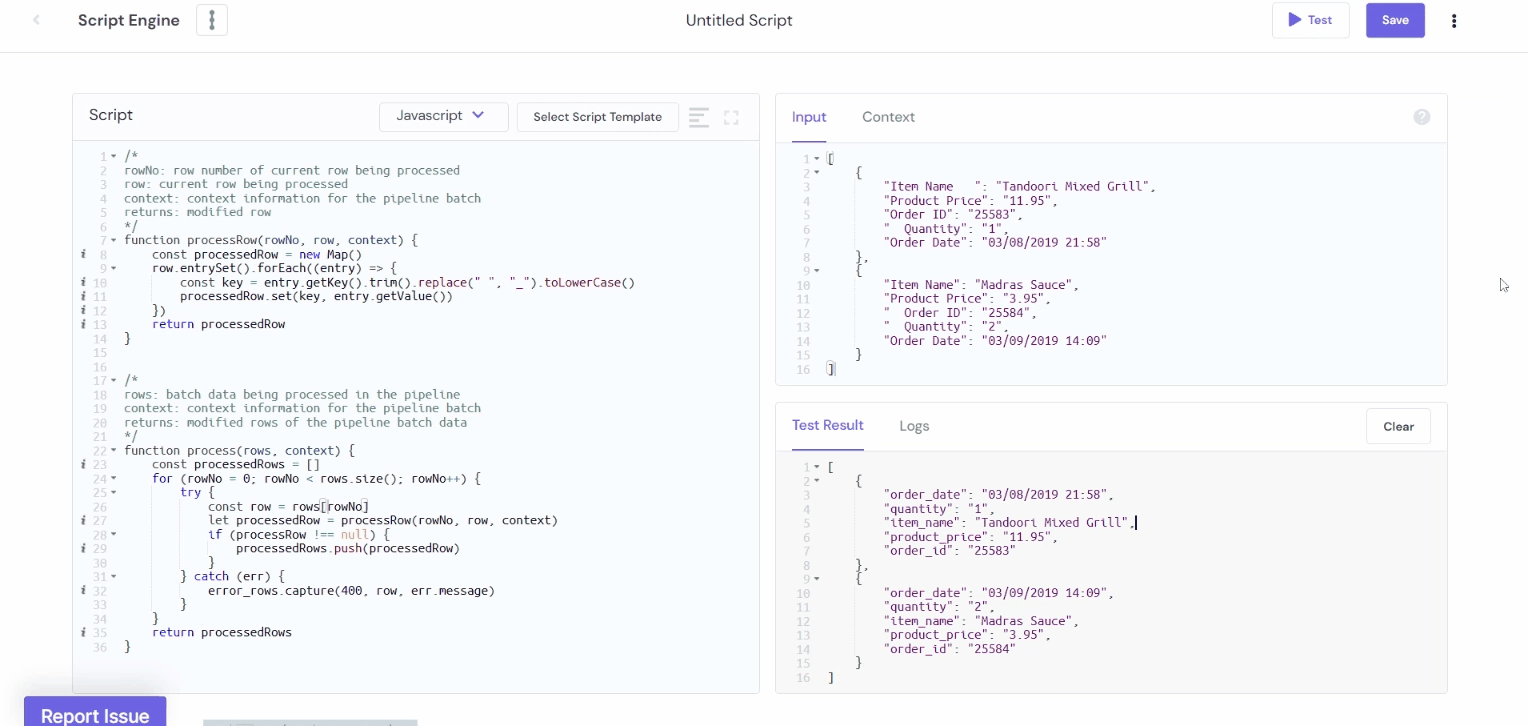
You can write a script to sanitize the column names through the script engine if needed. In the following example, we have replaced the spaces in column names with underscores(_) and trimmed the leading and trailing spaces.
Javascript
/*
rowNo: row number of current row being processed
row: current row being processed
context: context information for the pipeline batch
returns: modified row
*/
function processRow(rowNo, row, context) {
const processedRow = new Map()
row.entrySet().forEach((entry) => {
const key = entry.getKey().trim().replace(" ", "_").toLowerCase()
processedRow.set(key, entry.getValue())
})
return processedRow
}
/*
rows: batch data being processed in the pipeline
context: context information for the pipeline batch
returns: modified rows of the pipeline batch data
*/
function process(rows, context) {
const processedRows = []
for (rowNo = 0; rowNo < rows.size(); rowNo++) {
try {
const row = rows[rowNo]
let processedRow = processRow(rowNo, row, context)
if (processRow !== null) {
processedRows.push(processedRow)
}
} catch (err) {
error_rows.capture(400, row, err.message)
}
}
return processedRows
}
Python
"""
rowNo: row number of current row being processed
row: current row being processed
context: context information for the pipeline batch
returns: modified row
"""
def process_row(row_no, row, context):
processed_row = {}
for entry in row.entrySet():
key = entry.getKey().strip().replace(" ", "_").lower()
processed_row[key] = entry.getValue();
return processed_row
return row
"""
rows: batch data being processed in the pipeline
context: context information for the pipeline batch
returns: modified rows of the pipeline batch data
"""
def process(rows, context):
processed_rows = []
for row_no, row in enumerate(rows):
try:
processed_row = process_row(row_no, row, context)
if processed_row is not None:
processed_rows.append(processed_row)
except Exception as e:
error_rows.capture(400, row, str(e))
return processed_rows
:::
Output:
Example 2: Cleaning a Column Value
Data cleaning is one of the essential steps in Transformation. It can be done in many ways, such as handling missing values, passing a default value in the place of null, or so on. The second example shows you we have cleaned an "Order Priority" column by replacing the values "L," "M," and "H" with "LOW," "MEDIUM," and "HIGH."
Javascript
// Enter the column name where data cleaning is required
const columName = "Order Priority"
// Map all the orginal column values to be replaced by new values
const valuesMap = {
"L": "LOW",
"M": "MEDIUM",
"H": "HIGH"
}
/*
rowNo: row number of current row being processed
row: current row being processed
context: context information for the pipeline batch
returns: modified row
*/
function processRow(rowNo, row, context) {
var columValue = row.get(columName)
var newValue = valuesMap[columValue]
if (!newValue) {
newValue = "MEDIUM" // add default value if no original value found to be replaced
}
row.put(columName, newValue)
return row
}
/*
rows: batch data being processed in the pipeline
context: context information for the pipeline batch
returns: modified rows of the pipeline batch data
*/
function process(rows, context) {
const processedRows = []
for (rowNo = 0; rowNo < rows.size(); rowNo++) {
try {
const row = rows[rowNo]
let processedRow = processRow(rowNo, row, context)
if (processRow !== null) {
processedRows.push(processedRow)
}
} catch (err) {
error_rows.capture(400, row, err.message)
}
}
return processedRows
}
Python
# Map all the orginal column values to be replaced by new values
values_map = {
"L": "LOW",
"M": "MEDIUM",
"H": "HIGH"
}
"""
rowNo: row number of current row being processed
row: current row being processed
context: context information for the pipeline batch
returns: modified row
"""
def process_row(row_no, row, context):
colum_name = "Order Priority" # enter the column name where data cleaning is required
colum_value = row[colum_name]
if (colum_value in values_map):
new_value = values_map[colum_value]
else:
new_value = "MEDIUM" # add default value if no original value found to be replaced
row[colum_name] = new_value
return row
"""
rows: batch data being processed in the pipeline
context: context information for the pipeline batch
returns: modified rows of the pipeline batch data
"""
def process(rows, context):
processed_rows = []
for row_no, row in enumerate(rows):
try:
processed_row = process_row(row_no, row, context)
if processed_row is not None:
processed_rows.append(processed_row)
except Exception as e:
error_rows.capture(400, row, str(e))
return processed_rows
Output:
Example 3: Validating Data Using Pattern Matching
To ensure the data is formatted as expected before sending it to the destination, you can validate it using pattern matching. For example, you can validate the pattern of the phone number, email address, dates, postal codes, and many more fields through JavaScript and Python.
Assume a data that contains columns: Restaurant Name, Address, Locality, and Contact. To check the validity of the row, the value against the column Contact should be in the appropriate email address (@ symbol is required). If appropriate, it shows "True" or otherwise "False."
JavaScript
/*
validateColumn: The column for which values are to be validated
pattern: The regex pattern that determines whether the input
is valid or not
To learn more about pattern matching and regular expressions,
visit https://www.w3schools.com/jsref/jsref_obj_regexp.asp
*/
var validateColumn = "contact"
var pattern = /^[^\s@]+@[^\s@]+\.[^\s@]+$/ // Validates email addresses
/*
input: the input string that needs to be validated
returns: true if the pattern matches, else false
*/
function isValidPattern(input) {
return pattern.test(input)
}
/*
rowNo: row number of current row being processed
row: current row being processed
context: context information for the pipeline batch
returns: modified row
*/
function processRow(rowNo, row, context) {
var columnValue = row[validateColumn]
var columnName = `is_${validateColumn}_valid`
row[columnName] = isValidPattern(columnValue)
return row
}
/*
rows: batch data being processed in the pipeline
context: context information for the pipeline batch
returns: modified rows of the pipeline batch data
*/
function process(rows, context) {
const processedRows = []
for (rowNo = 0; rowNo < rows.size(); rowNo++) {
try {
const row = rows[rowNo]
let processedRow = processRow(rowNo, row, context)
if (processRow !== null) {
processedRows.push(processedRow)
}
} catch (err) {
error_rows.capture(400, row, err.message)
}
}
return processedRows
}
Python
import re
"""
validate_column: The column for which values are to be validated
pattern: The regex pattern that determines whether the input
is valid or not
To learn more about pattern matching and regular expressions,
visit https://www.w3schools.com/python/python_regex.asp
"""
validate_column = "contact"
pattern = r"[^\s@]+@[^\s@]+\.[^\s@]+" # Validates email addresses
regex = re.compile(pattern)
"""
input: the input string that needs to be validated
returns: true if the pattern matches, else false
"""
def is_valid_pattern(input):
return bool(regex.fullmatch(input))
"""
row_no: row number of current row being processed
row: current row being processed
context: context information for the pipeline batch
returns: modified row
"""
def process_row(row_no, row, context):
column_value = row[validate_column]
columnName = f"is_{validateColumn}_valid"
row["is_valid"] = is_valid_pattern(column_value)
return row
"""
rows: batch data being processed in the pipeline
context: context information for the pipeline batch
returns: modified rows of the pipeline batch data
"""
def process(rows, context):
processed_rows = []
for row_no, row in enumerate(rows):
try:
processed_row = process_row(row_no, row, context)
if processed_row is not None:
processed_rows.append(processed_row)
except Exception as e:
error_rows.capture(400, row, str(e))
return processed_rows
:::
Output:
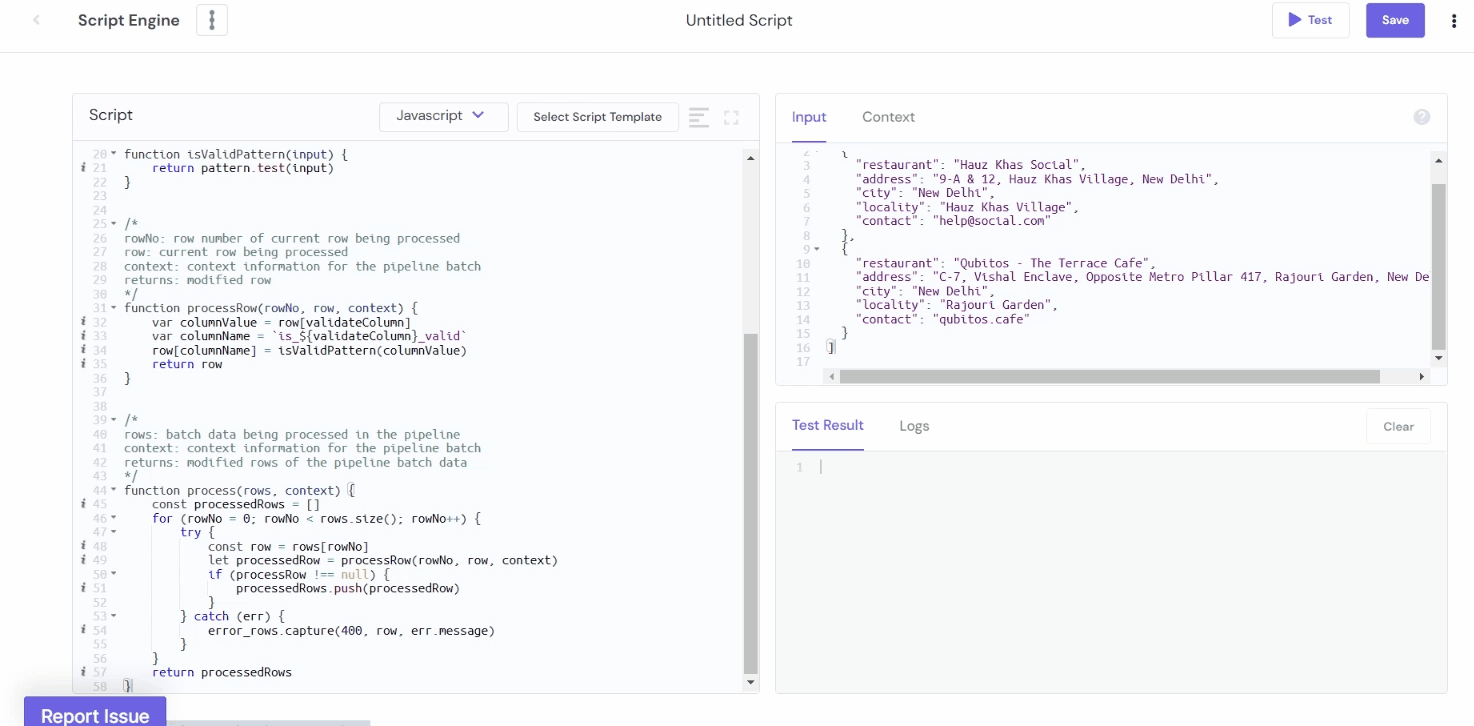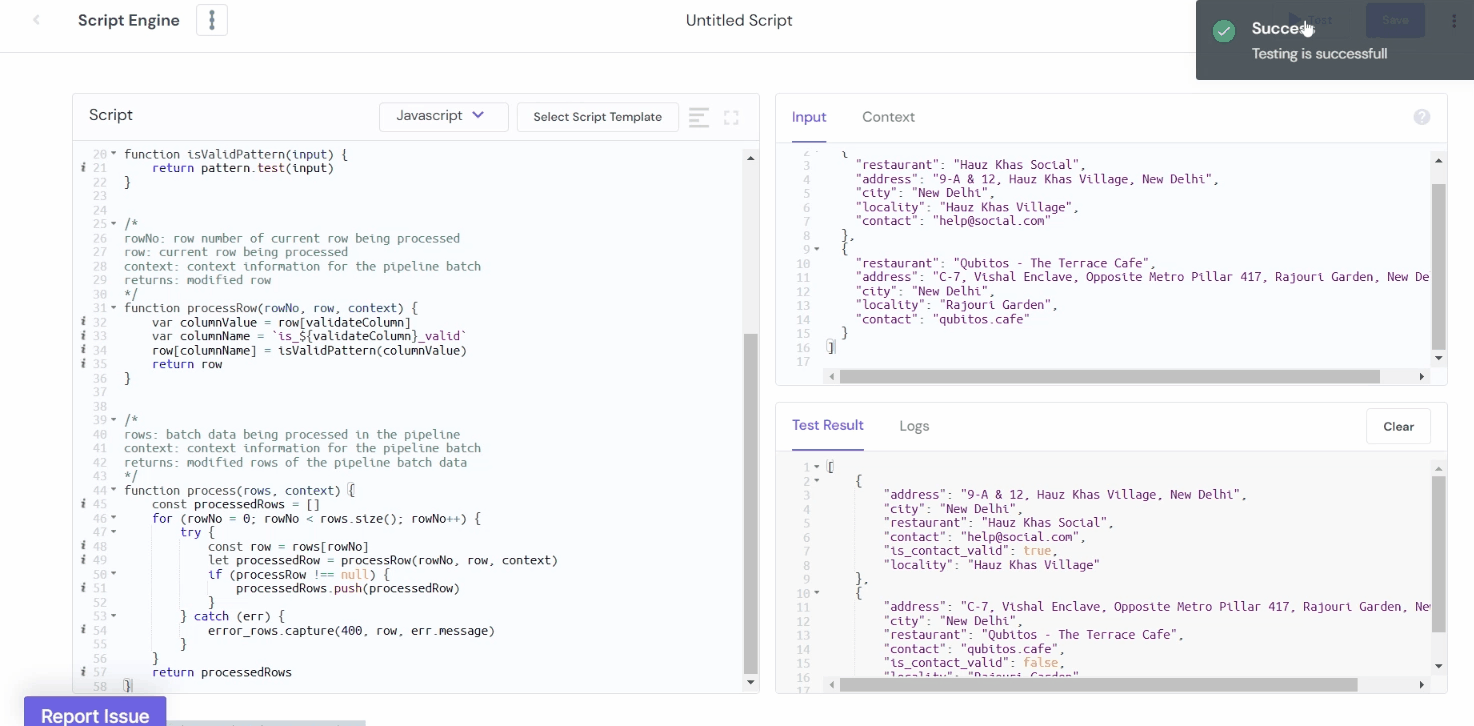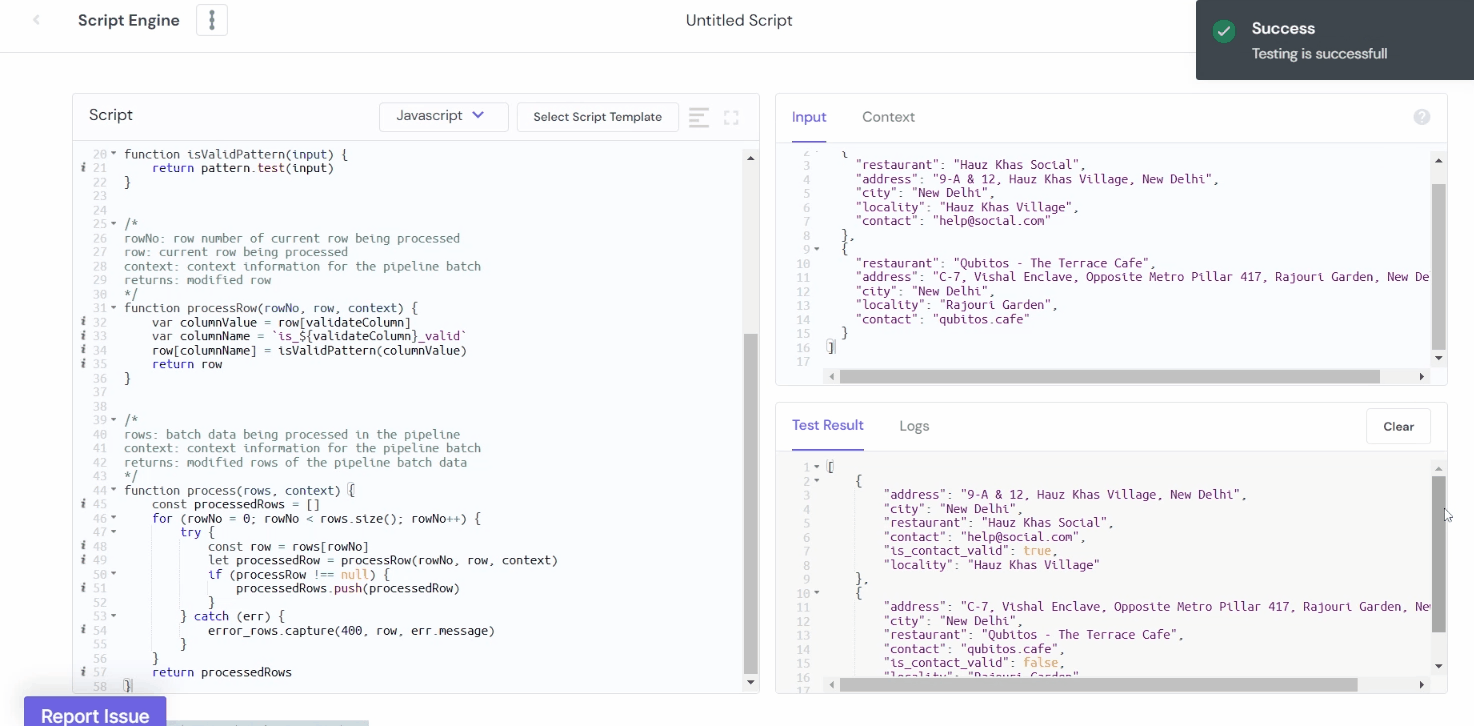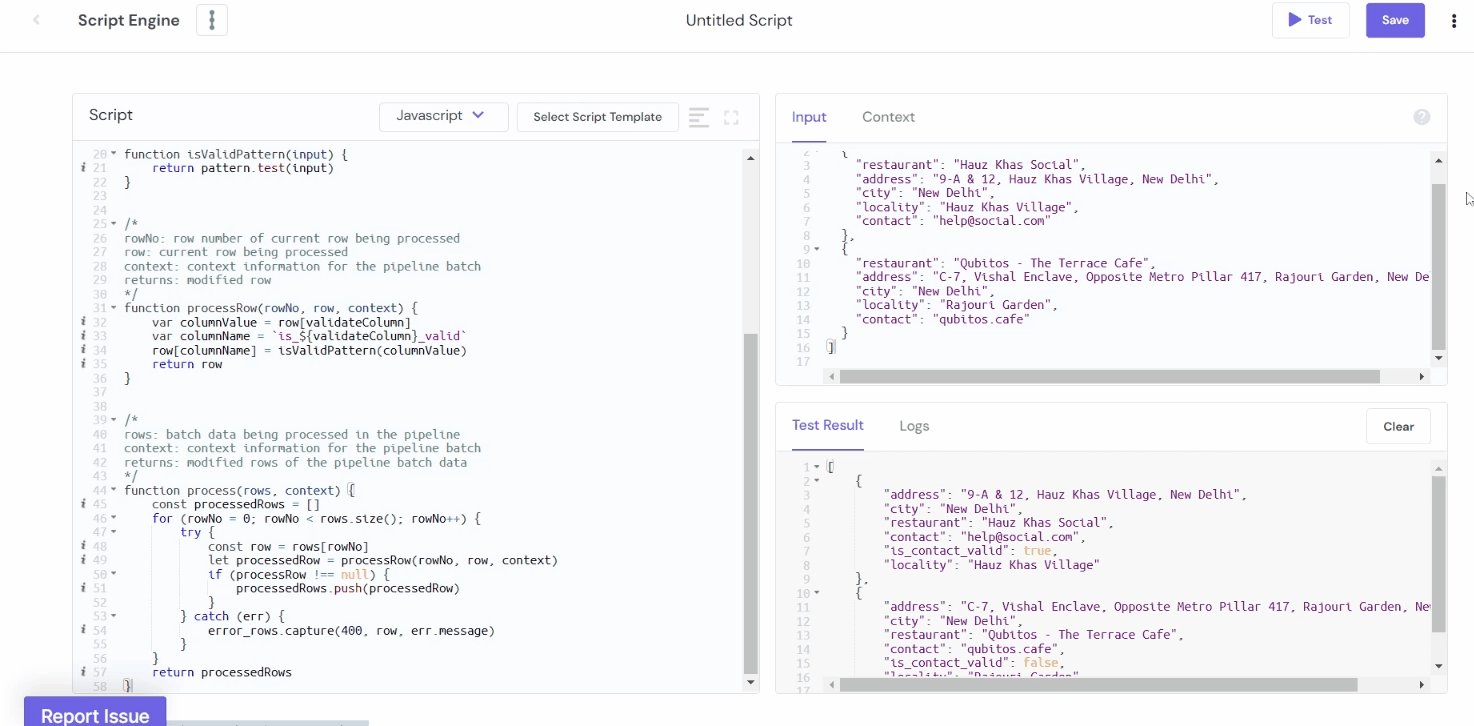
Example 4: Sum and Count Aggregations
The mathematical operations such as Sum, Avg, Count, and so on can be applied to the data using JavaScript and Python. For example, assume there's a Sales Records data of the XYZ company, and we'd like to figure out how much profit we've made on all of our product sales and the overall cost of the products. However, we have two sales channels: online and offline, via which we offer products in different parts of the world.
Here's how we may determine sales success by breaking down overall cost and profit by sales channels and region, as well as the count of unique item categories sold to each region through each channel.
Note
To simplfy scripting and make it more succient,consistent and clean use Lodash library.
Always declare a variable with const unless you know that the value will change
Javascript
var lodash = require('lodash');
/*
sumAggregations: Enter the column names for which sum aggregations are required
countAggregations: Enter the column names for which count aggregations are required
groupByColumns: Enter the column keys on which aggregations are grouped by
Examples - ["first_column", "second_column"]
Note: Keep the list empty if any aggregation or grouping is not required.
This script works best when you're processing your entire data in one batch.
*/
const sumAggregations = ["Total Cost", "Total Profit"]
const countAggregations = ["Item Type"]
const groupByColumns = ["Sales Channel", "Region"]
function generateGroupKey(row) {
var keys = []
groupByColumns.forEach(column => {
keys.push(row[column])
})
return keys.join(" | ")
}
/*
row: current row for which values have to be parsed
returns: modified rows with parsed values for columns
which are to be aggregated
*/
function parseValues(row) {
try {
sumAggregations.forEach((column) => {
var columnValue = row[column]
if (columnValue) {
row[column] = parseFloat(columnValue)
}
})
return row
} catch (err) {
error_rows.capture(400, row, err.message)
}
}
/*
rows: rows grouped by the given key
key: the key on which aggregation is grouped by
context: context information for the pipeline batch
returns: row containing aggregations for the given key
*/
function aggregateRows(rows, keys, context) {
var aggregatedRow = {}
keys = keys.split(" | ")
groupByColumns.forEach((column, index) => {
aggregatedRow[column] = keys[index]
})
sumAggregations.forEach((column) => {
aggregatedRow[column] = lodash.sumBy(rows, column)
})
countAggregations.forEach((column) => {
aggregatedRow[column + " Count"] = lodash.uniqBy(rows, column).length
})
aggregatedRow["batch_no"] = context.getBatchNo()
return aggregatedRow
}
/*
rows: batch data being processed in the pipeline
context: context information for the pipeline batch
returns: modified rows of the pipeline batch data
*/
function process(rows, context) {
var results = lodash(rows)
.map(row => parseValues(row))
.groupBy(row => generateGroupKey(row))
.map((rows, keys) => aggregateRows(rows, keys, context))
.value()
return results
}
Python
from itertools import groupby
"""
sum_aggregations: Enter the column names for which sum aggregations are required
count_aggregations: Enter the column names for which count aggregations are required
group_by_columns: Enter the column keys on which aggregations are grouped by
Examples - ["first_column", "second_column"]
Note: Keep the list empty if any aggregation or grouping is not required.
This script works best when you're processing your entire data in one batch.
"""
sum_aggregations = ["Total Cost", "Total Profit"]
count_aggregations = ["Item Type"]
group_by_columns = ["Sales Channel", "Region"]
def generate_group_key(row):
keys = []
for column in group_by_columns:
keys.append(row[column])
return " | ".join(keys)
"""
row: current row for which values have to be parsed
returns: modified rows with parsed values for columns
which are to be aggregated
"""
def parse_values(row):
try:
for column in sum_aggregations:
if column in row:
parsed_value = float(row[column])
row[column] = parsed_value
return row
except Exception as e:
error_rows.capture(400, row, str(e))
"""
rows: rows grouped by the given key
key: the key on which aggregation is grouped by
context: context information for the pipeline batch
returns: row containing aggregations for the given key
"""
def aggregate_rows(rows, key, context):
aggregated_row = {}
keys = key.split(" | ")
for (column, key_value) in zip(group_by_columns, keys):
aggregated_row[column] = key_value
for column in sum_aggregations:
sum_value = sum(row[column] for row in rows)
aggregated_row[column] = sum_value
for column in count_aggregations:
count_value = len(set(row[column] for row in rows))
aggregated_row[column + " Count"] = count_value
aggregated_row['batch_no'] = context.getBatchNo()
return aggregated_row
"""
rows: batch data being processed in the pipeline
context: context information for the pipeline batch
returns: modified rows of the pipeline batch data
"""
def process(rows, context):
aggregated_rows = []
sorted_rows = sorted(rows, key=generate_group_key)
for key, grouped_rows in groupby(sorted_rows, key=generate_group_key):
grouped_rows = map(parse_values, list(grouped_rows))
aggregated_row = aggregate_rows(list(grouped_rows), key, context)
aggregated_rows.append(aggregated_row)
return aggregated_rows
Output:
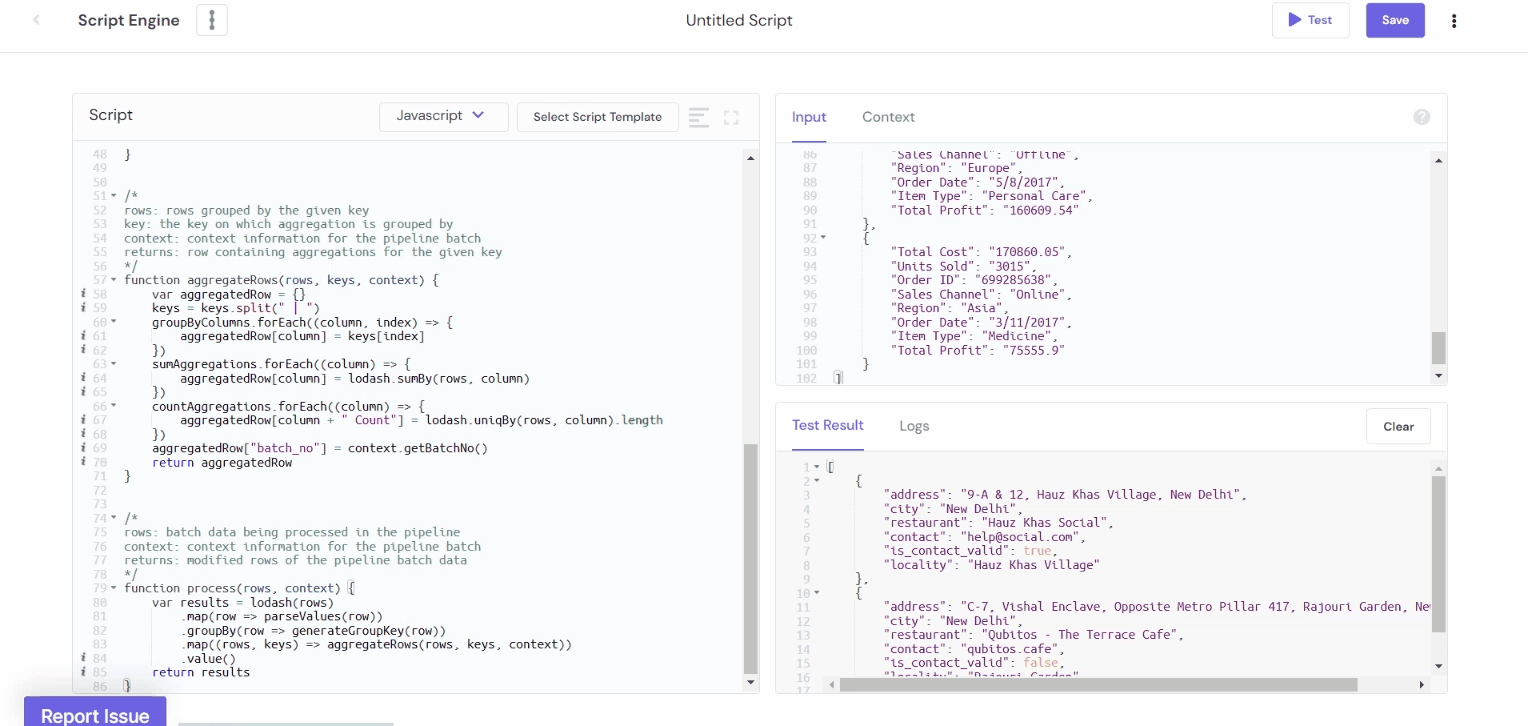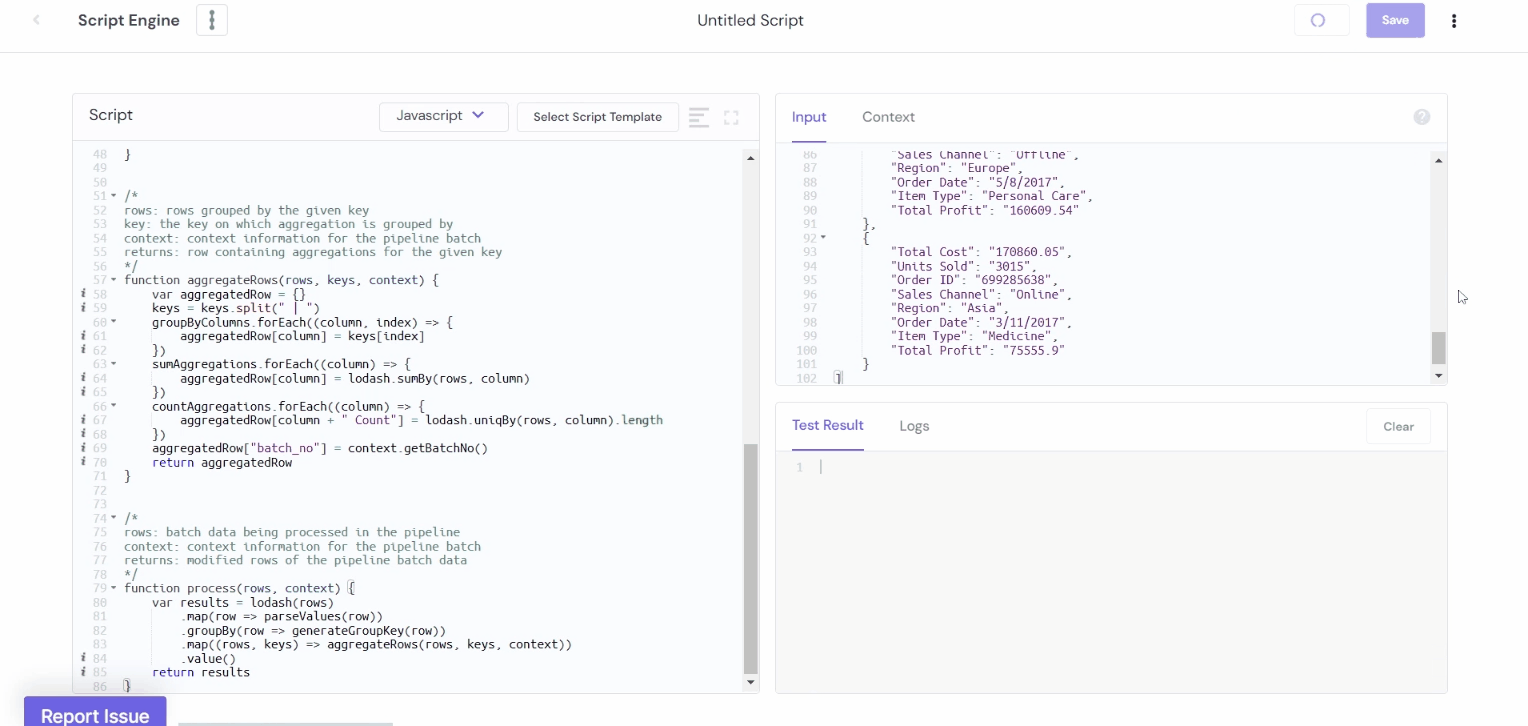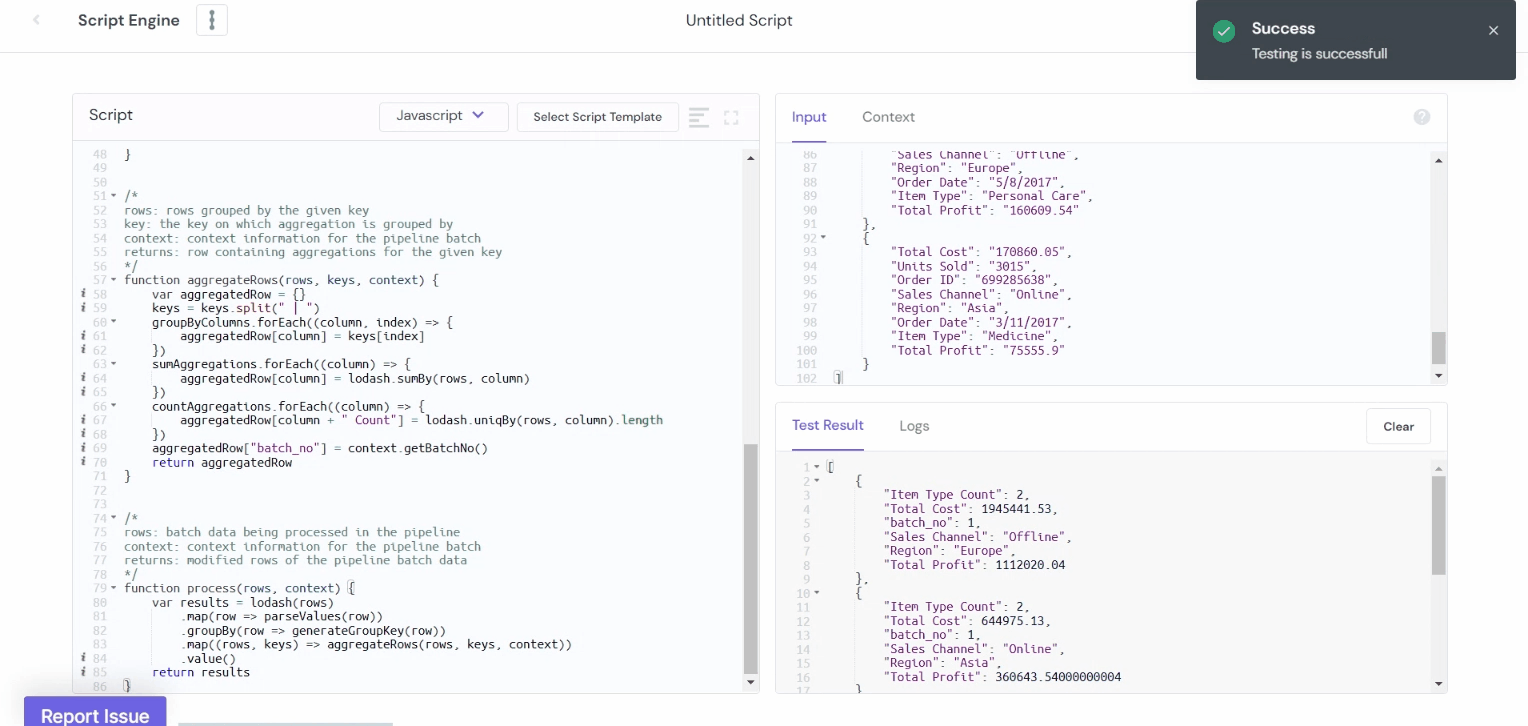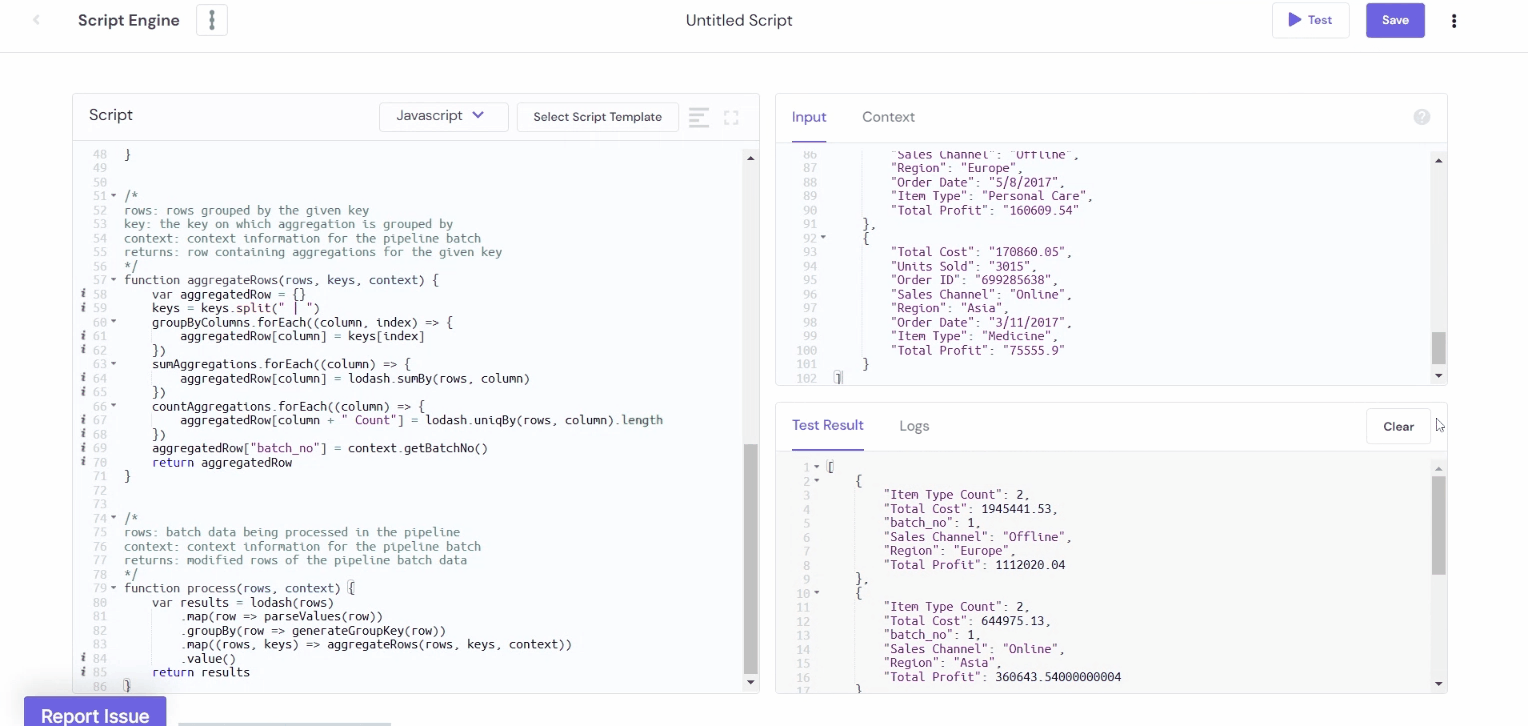
Example 4: Convert Date and Time Formats
In the following example, we have the time values stored in a string and converted them into a date format using the Moment library.
Javascript
var moment = require("moment");
/*
sourceColumn: column having the datetime string to be converted
sourceFormat: datetime format of the source column
targetColumn: column generated after datetime conversion of source column
targetFormat: datetime format of the target column
You may keep the target_column same as source_column
if you intend to replace it
For more info on datetime formats,
refer https://momentjscom.readthedocs.io/en/latest/moment/04-displaying/01-format/
Add more such configs to this list if you have other datetime columns
in the data and intend to convert them
*/
const sourceColumn = "Order Date"
const sourceFormat = "MM/DD/YYYY h:mm"
const targetColumn = "Order Month"
const targetFormat = "MMM YYYY"
/*
rowNo: row number of current row being processed
row: current row being processed
context: context information for the pipeline batch
returns: modified row
*/
function processRow(rowNo, row, context) {
var sourceDatetime = row[sourceColumn]
var parsedDateTime = moment(sourceDatetime, sourceFormat)
row[targetColumn] = parsedDateTime.format(targetFormat)
return row
}
/*
rows: batch data being processed in the pipeline
context: context information for the pipeline batch
returns: modified rows of the pipeline batch data
*/
function process(rows, context) {
const processedRows = []
for (rowNo = 0; rowNo < rows.size(); rowNo++) {
try {
const row = rows[rowNo]
let processedRow = processRow(rowNo, row, context)
if (processRow !== null) {
processedRows.push(processedRow)
}
} catch (err) {
error_rows.capture(400, row, err.message)
}
}
return processedRows
Python
from datetime import datetime
"""
source_column: column having the datetime string to be converted
source_format: datetime format of the source column
target_column: column generated after datetime conversion of source column
target_format: datetime format of the target column
You may keep the target_column same as source_column
if you intend to replace it
For more info on datetime formats, visit
https://docs.python.org/3/library/datetime.html#strftime-and-strptime-format-codes
"""
source_column = "Order Date"
source_format = "%m/%d/%Y %H:%M"
target_column = "Order Month"
target_format = "%b %Y"
"""
row_no: row number of current row being processed
row: current row being processed
context: context information for the pipeline batch
returns: modified row
"""
def process_row(row_no, row, context):
if source_column in row:
source_datetime = row[source_column]
parsed_datetime = datetime.strptime(source_datetime, source_format)
row[target_column] = parsed_datetime.strftime(target_format)
return row
"""
rows: batch data being processed in the pipeline
context: context information for the pipeline batch
returns: modified rows of the pipeline batch data
"""
def process(rows, context):
processed_rows = []
for row_no, row in enumerate(rows):
try:
processed_row = process_row(row_no, row, context)
if processed_row is not None:
processed_rows.append(processed_row)
except Exception as e:
error_rows.capture(400, row, str(e))
return processed_rows
Output:
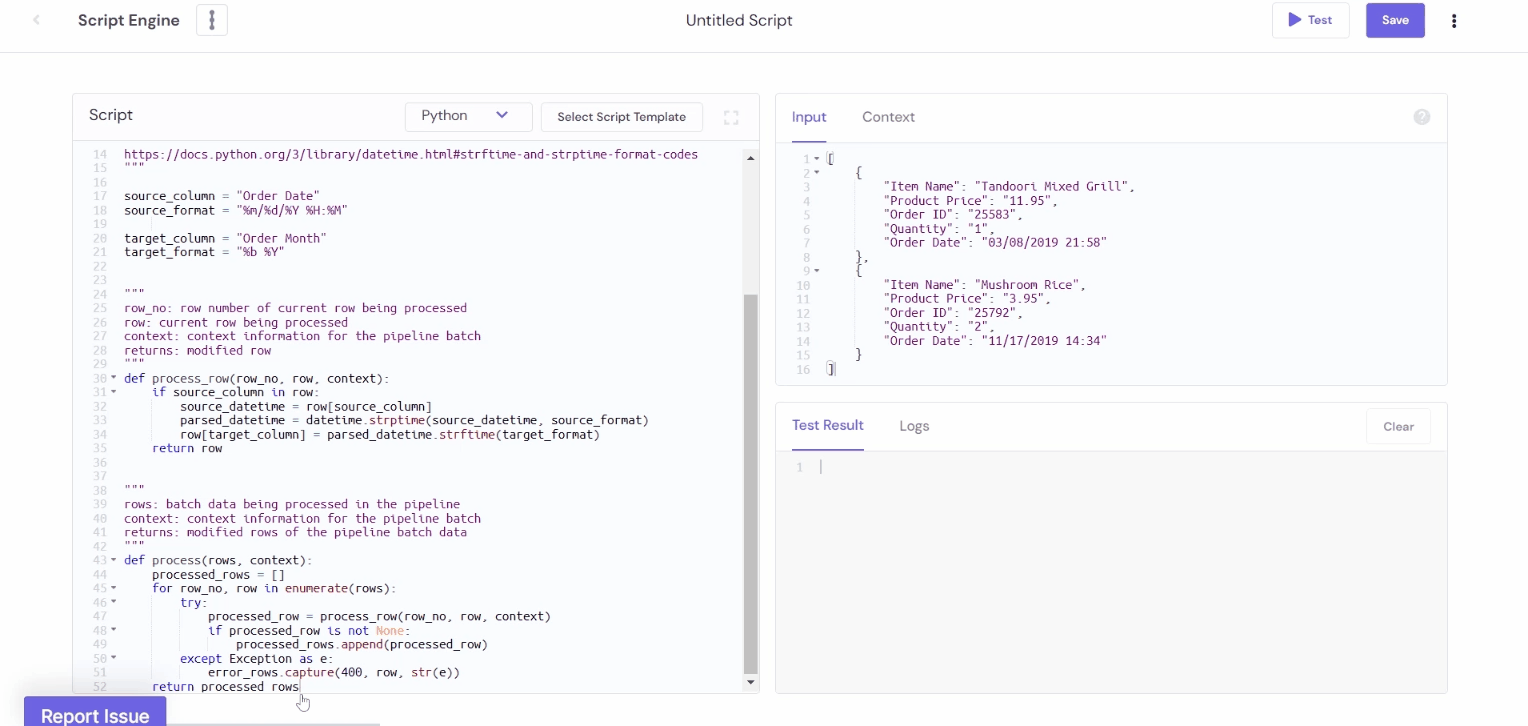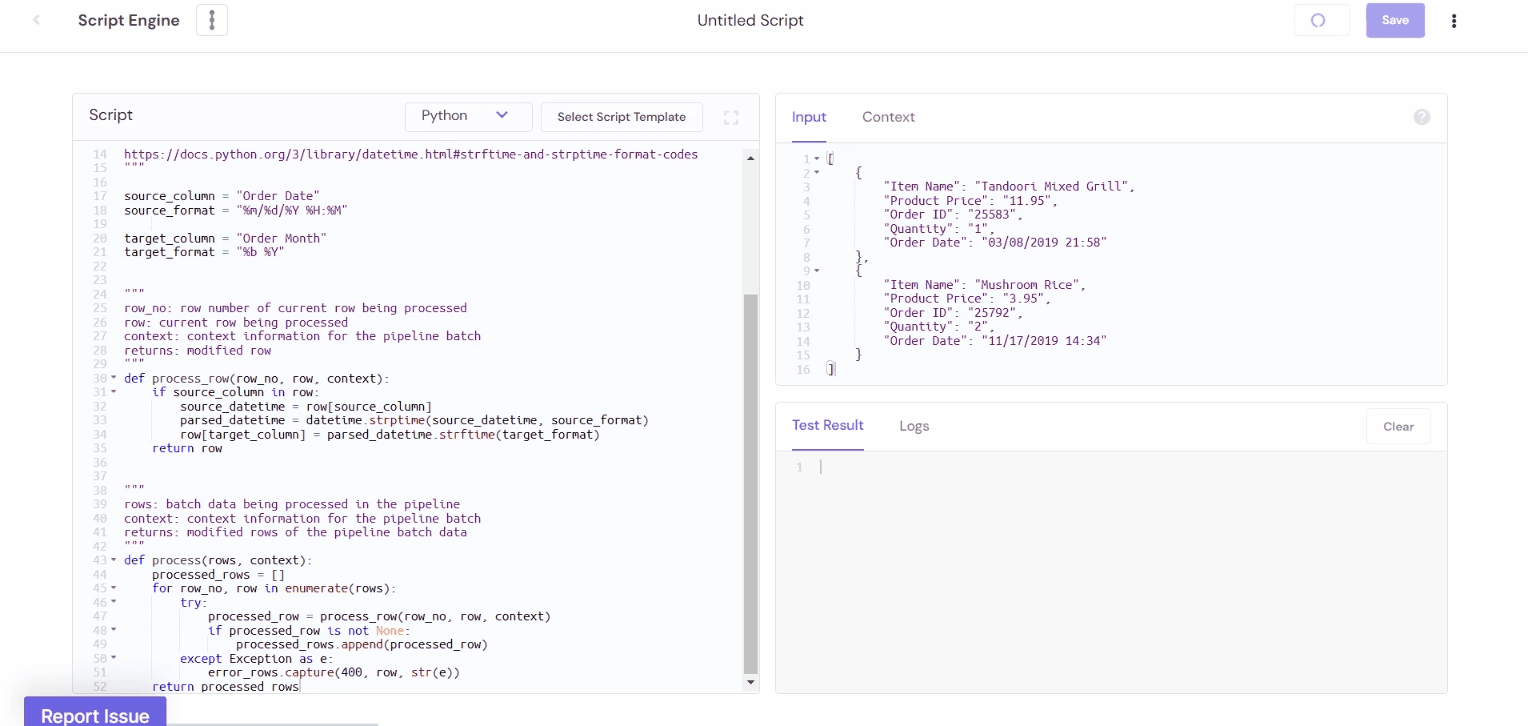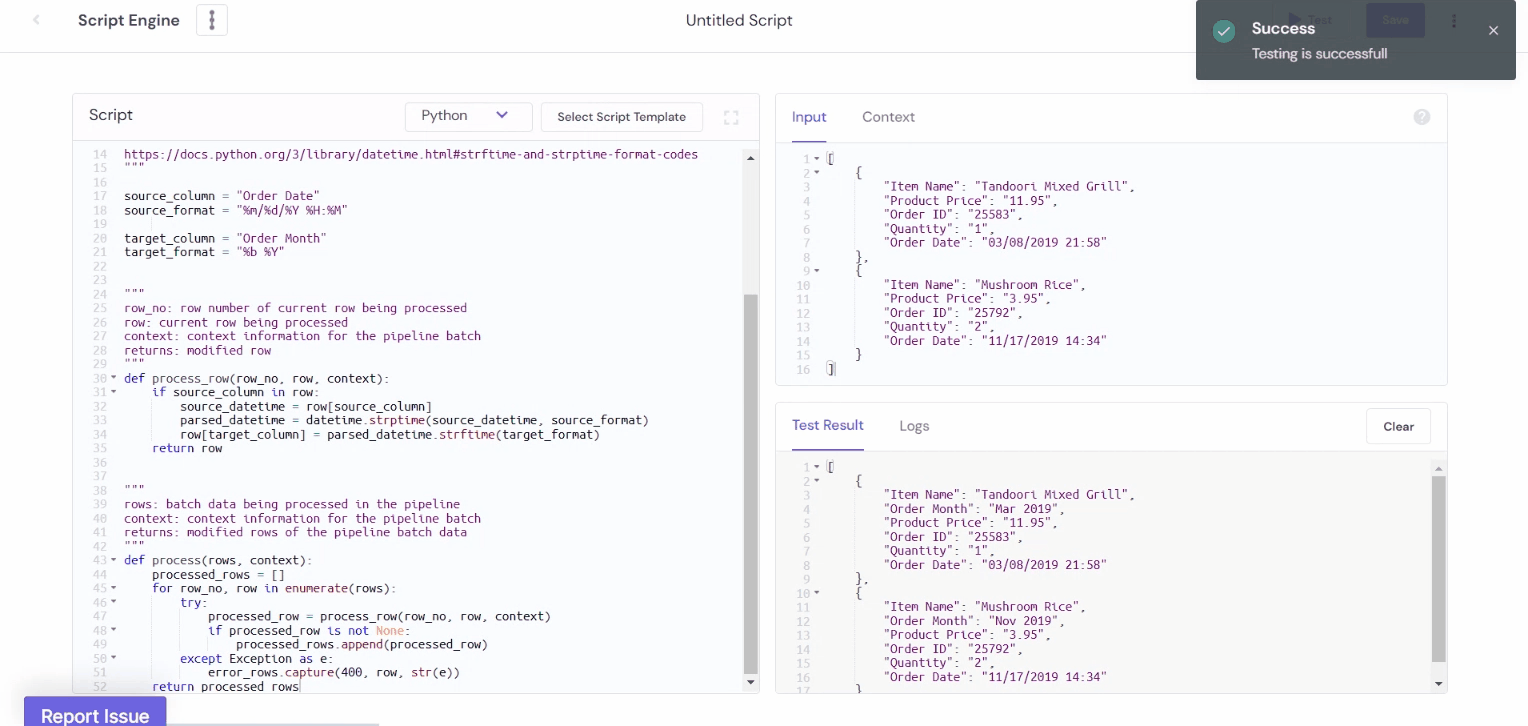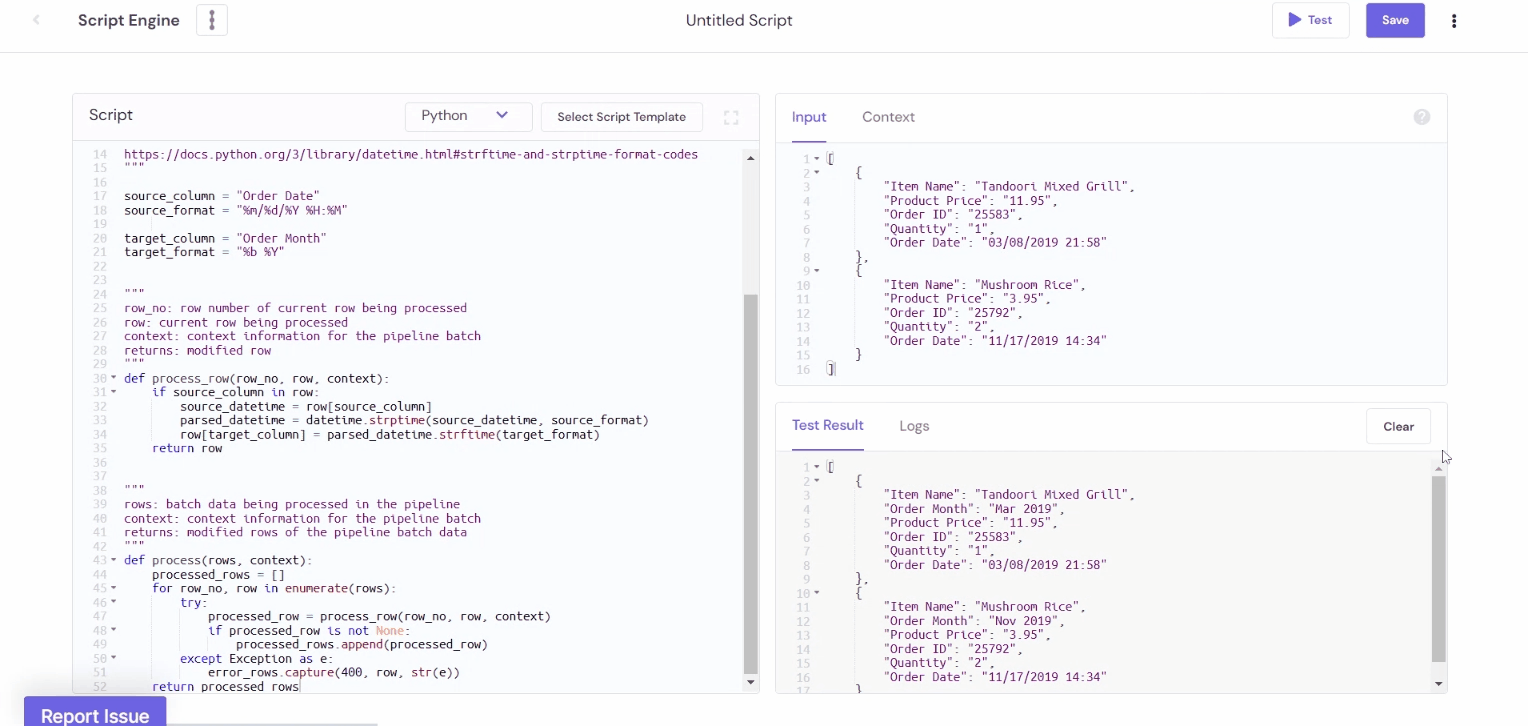
The usage of Javascript and Python is not limited to these examples. By writing scripts, you can transform any field of your data and make it more usable, cleaned, and enriched.
Any Question? 🤓
We are always an email away to help you resolve your queries. If you need any help, write to us at - 📧 support@boltic.io