






Data is extracted from numerous sources, transformed into a format that can be analyzed, and then loaded into a destination, such as a database or data warehouse, as part of the ETL process. It is a vital phase in the data pipeline that aids businesses' data interpretation and decision-making.
Because of its ease of use and adaptability, Python is a preferred programming language for ETL jobs. It contains many tools and frameworks that make it simple to carry out diverse ETL processes, such as connecting multiple data sources, cleaning and converting data, and loading it into a destination.
This article will examine the various Python ETL job use scenarios. We'll go over everything, including connecting to various data sources, cleaning and transforming the data, and then loading the data into a destination.
What are ETL Tools?

The three primary ETL operations—Extract, Transform, and LoadLoad—are carried out by ETL tools, or Extract, Transform, and Load tools. As they enable enterprises to understand their data and make wise decisions, these processes are essential in the data pipeline.
Data is gathered through the "Extract" function from various sources, including databases, CSV files, and APIs. The ETL tool may then read the data when it has been extracted into that format.
The process of transforming the retrieved data into a format appropriate for analysis is known as the "Transform" operation. This operation can entail cleaning up the data, eliminating pointless columns, or changing data types.
The "Load" action transfers the changed data to a target location, such as a database or data warehouse. This step is crucial because it allows the data to be stored in a structured format that can be easily queried and analyzed.
ETL tools can be divided into then-source, commercial, and Python-based. Open-source ETL tools are free to use and are typically open-source projects. Commercial ETL tools are typically paid for and are often provided by more significant software vendors.
Python-based ETL tools are built using the Python programming language and are well-suited for small to medium-sized data pipelines.
When choosing an ETL tool, it's essential to consider your organization's specific needs and the size and complexity of your data pipeline. While Python-based tools can be excellent for smaller data pipelines, open-source and commercial technologies may be better appropriate for more extensive and sophisticated projects.
In conclusion, ETL tools are software programs that assist companies in extracting, transforming, and loading data from various sources into a structured format that is simple to query and analyze.
These tools come in open-source, paid, and Python-based variations. The organization's unique demands and the size and complexity of the data flow will determine which should be used.
What are Python ETL Tools?
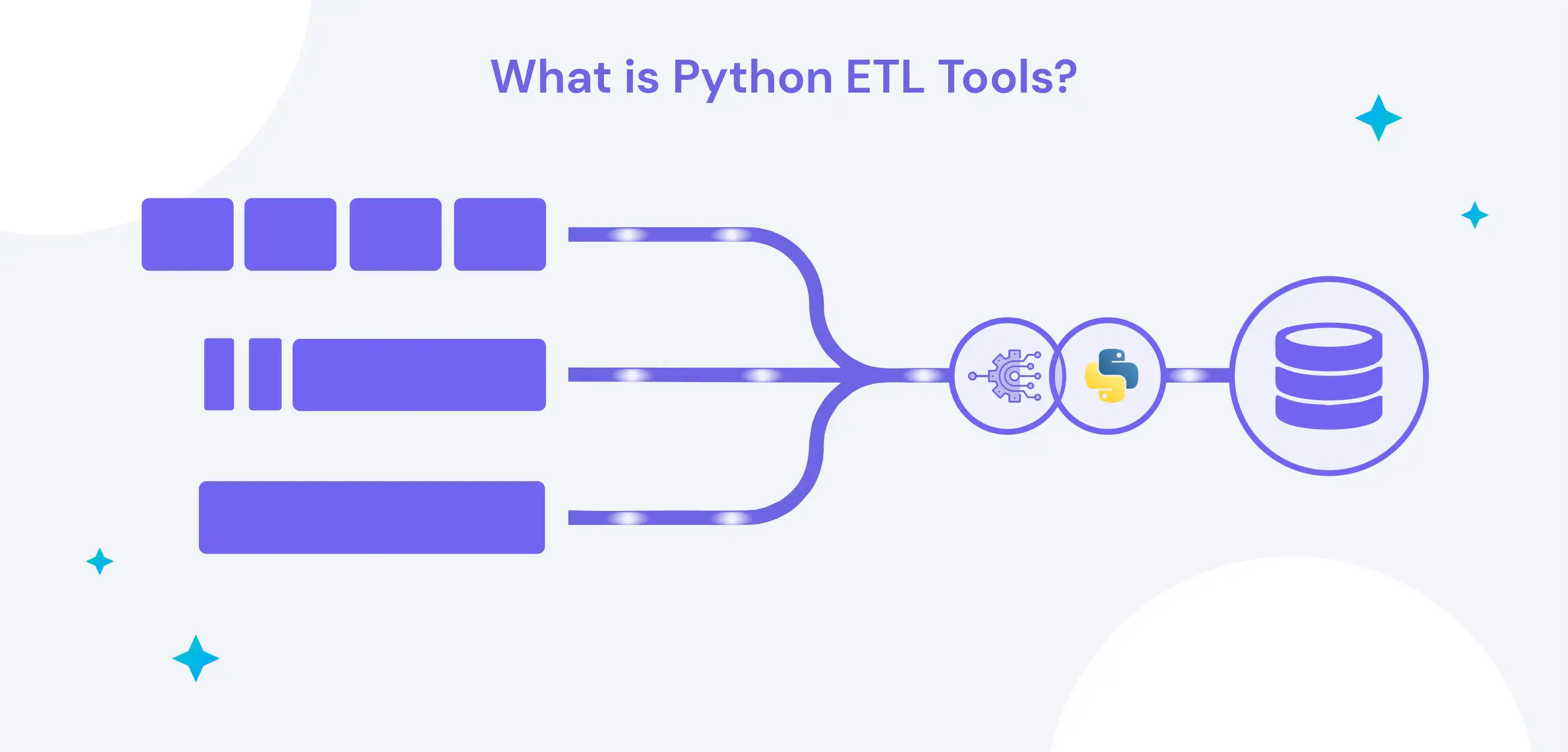
Anyone wishing to utilize Python for Extract, Transform, and Load (ETL) operations needs to know the definition of Python ETL Tools.
Data extraction, transformation, and loading (ETL) from various sources into a target database or data warehouse are all made possible by Python ETL tools, which are computer programs. These tools offer numerous data integration and administration functions and are specially designed to work with Python.
Python ETL solutions' primary objective is to automate the data integration process and improve how effectively and efficiently businesses can manage and analyze their data. These solutions let businesses gather data from many sources, clean it up, and format it uniformly before loading it into a centralized data repository for additional research.
Python ETL tools support most data sources, including databases, files, web services, and APIs. Additionally, they provide a wide range of data cleansing, validation, and transformation functions, such as data profiling, mapping, quality checks, and normalization.
The flexibility and scalability of Python ETL solutions are two of its main benefits. These tools may be readily adjusted to support additional data sources and formats and are intended to be highly responsive to changing data requirements.
Furthermore, Python ETL solutions are suited for big data situations because they can quickly expand to accommodate massive volumes of data.
The simplicity of usage of Python ETL tools is another benefit. These solutions' user-friendly interfaces, extensive feature sets, and functions make it simple for developers and data analysts to carry out challenging data integration tasks.
Users may rapidly and simply do data extraction, transformation, and loading with Python ETL tools without human scripting.
To sum up, Python ETL technologies give businesses a robust and adaptable way to manage and integrate their data. These solutions can assist you more successfully and efficiently in achieving your data integration goals, regardless of whether you are working with extensive data or need to handle several data sources.
Python ETL solutions are needed for businesses that wish to properly manage and analyze their data because of their robust features, usability, and scalability.
Significance of Python ETL Tools
Python ETL solutions is necessary because they can expedite and automate the process of extracting, processing, and loading data. These solutions enable businesses to easily collect data from several sources, clean and modify it, and put it into a destination for analysis and reporting.
One of the essential advantages of Python ETL solutions is their adaptability. Python is a general-purpose programming language that may be used for various tasks, including data processing and analysis. This processing enables enterprises to employ Python ETL tools to handle various data sources and formats.
Scalability is another critical benefit of Python ETL tools. Python is a simple-to-learn and uses a high-level programming language. Both small and big and sophisticated data pipelines may be handled with Python ETL tools.
Additionally, Python ETL solutions offer a wide range of features that may be quickly incorporated into an organisations current data pipeline, including data validation, transformation, and integration. This workflow can significantly increase how well data is processed and analysed.
Tools for Python ETL are also reasonably priced. Many well-known Python ETL solutions are open-source and cost-free, saving businesses a lot of money on software.
Finally, there is a sizable and vibrant community for Python ETL tools. This statement implies that developers may contribute to the development of the tools and readily obtain assistance and support while using Python ETL tools.
In conclusion, Python ETL tools are essential for their capacity to automate and simplify data extraction, transformation, and loading. They are an excellent option for businesses trying to enhance their data pipeline since they are adaptable, scalable, offer a wide range of features, are affordable, and have a sizable and vibrant community.
How to use Python for ETL?
Python automates and streamlines data processing and analysis throughout the ETL (Extract, Transform, Load) process. Depending on the demands of the company, the size, and the complexity of the data pipeline, various methods may be employed to employ Python for ETL.
A popular strategy is using a Python ETL tool like Apache Airflow, Luigi, Bonobo, or Pandas. These programs offer numerous functions, including data validation, transformation, and integration, and are mainly made to do ETL jobs using Python.
Another strategy involves using Python libraries like NumPy and pandas for data cleansing and manipulation, PyMySQL, psycopg2, and PyMongo for database connections and data extraction, and Dask, PySpark, and Pandas for parallel processing on sizable datasets.
Additionally, Python libraries like requests and lovely soup may be used for web scraping, in addition to built-in libraries like CSV, JSON, and XML for reading and writing files.
Understanding the data sources and the company's unique requirements is crucial when using Python for ETL. Having a clear strategy for the data pipeline is crucial, and it is crucial to test and debug the code often.
Python is an effective tool for automating and streamlining data processing and analysis. Python ETL tools or libraries, Python built-in libraries, and Python libraries for web scraping and database connectivity are some of the methods that may be employed. When utilizing Python for ETL, it's critical to have a thorough grasp of the data sources, the unique requirements of the company, and a detailed plan for the data pipeline.
How to build an ETL pipeline with Python
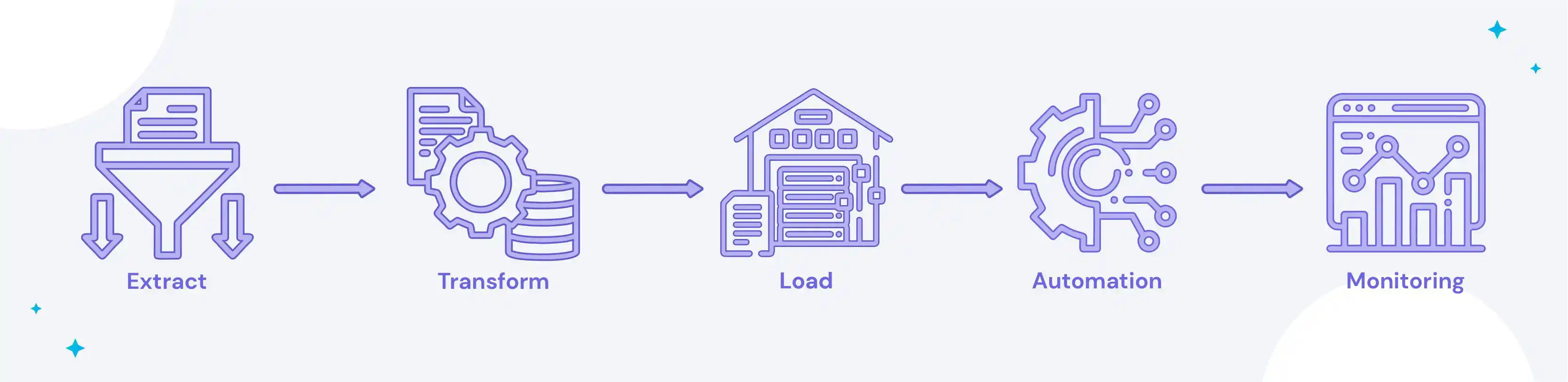
Building an ETL (Extract, Transform, Load) pipeline can be challenging, especially when dealing with large amounts of data. The good news is that building an ETL pipeline is simple, thanks to Python, a potent tool. This post will examine the procedures for setting up a Python ETL pipeline.
- Extracting the data: The first step in building an ETL pipeline is to extract the data from its source. This process can be done using various methods, such as reading from a file, accessing an API, or querying a database. Python has several libraries, such as Pandas, Requests, and SQLAlchemy, that can be used for data extraction.
- Transforming the data: The next step is transforming it to make it usable for further analysis. This procedure can involve cleaning the data, converting it to a suitable format, and aggregating it. Python has several libraries, such as Numpy, Scipy, and Pandas, that can be used for data transformation.
- Loading the data: The final step is to load the transformed data into a data store. This data store can be a database, warehouse, or data lake. Python has several libraries, such as SQLAlchemy, PyMySQL, and PySpark, that can be used for data loading.
- Automating the pipeline: To make the ETL pipeline efficient and scalable, automating the pipeline process is essential. This process can be achieved using a scheduler, such as Apache Airflow, to run the pipeline at set intervals.
- Monitoring the pipeline: Finally, it's crucial to monitor the pipeline to ensure it's running as expected and to identify any errors. Python has several libraries, such as TensorFlow, that can monitor the pipeline.
In conclusion, building an ETL pipeline with Python is a straightforward process that can be achieved using the right tools and techniques. By extracting the data, transforming it, loading it, automating the pipeline, and monitoring it.
You can build a robust and scalable ETL pipeline that can easily handle large amounts of data. With these best practices, you can use Python ETL for your data operations.
Top 13 Python ETL Tools
1. Apache Airflow:

This open-source tool is one of the most popular Python ETL tools. It allows users to create, schedule, and monitor data pipelines and provides a web-based user interface for managing and monitoring the pipeline.
Some critical functionalities of Apache Airflow include data validation, transformation, and integration, as well as built-in support for various data sources and destinations.
2. Luigi:

Another open-source tool, Luigi, is a Python library for building complex pipelines of batch jobs. It is simple and allows users to build flexible and scalable pipelines. Some of its critical functionalities of Luigi include data validation, transformation, and integration, as well as support for running jobs in parallel.
3. Pandas:

This open-source library is widely used for data manipulation and analysis in Python. It provides robust data structures and analysis tools that make it easy to work with and clean data. Pandas' key functionalities include data wrangling, cleaning, and exploration.
4. Bonobo:

This open-source tool provides a simple, lightweight way to create data pipelines using Python. It is easy to use and allows users to create data pipelines that are both flexible and scalable.
Some of the critical functionalities of Bonobo include data validation, transformation, and integration, as well as support for running jobs in parallel.
5. Pete:

This open-source library provides a lightweight, simple way to extract, transform, and LoadLoad data in Python. It is easy to use and allows users to create data pipelines that are both flexible and scalable.
Some critical functionalities of "Pete" include data validation, transformation, integration, and support for running jobs in parallel.
6. PySpark:

PySpark is the Python library for Spark programming. It provides an interface for programming Spark with the Python programming language. Some critical functionalities of PySpark include distributed data processing, validation, transformation, and integration.
7. Odo:
This open-source library provides a simple and lightweight way to move data between different data sources and formats. It is easy to use and allows users to create data pipelines that are both flexible and scalable.
Some of the critical functionalities of Odo include data validation, transformation, and integration, as well as support for running jobs in parallel.
8. Metal:
This open-source tool provides a simple, lightweight way to create data pipelines using Python. It is easy to use and allows users to create data pipelines that are both flexible and scalable.
Some critical functionalities of mETL include data validation, transformation, and integration, as well as support for running jobs in parallel.
9. Riko:
This open-source tool provides a simple, lightweight way to create data pipelines using Python. It is easy to use and allows users to create data pipelines that are both flexible and scalable. Riko's critical functionalities include data validation, transformation, integration, and support for running jobs in parallel.
10. Task:
Dask is a versatile Python module for parallel analytics computation. Users may utilize all of their CPU and memory resources thanks to it. Parallel computing, data validation, transformation, and integration are some of the crucial Dask features.
11. Talend:

Talend is a powerful ETL tool that is widely used for data integration. It provides a wide range of functionalities for data integration and data quality. Talend's key functionalities include data validation, transformation, integration, and support for running jobs in parallel, making it an ideal choice for large and complex ETL projects.
Talend offers a visual interface for designing and executing data integration processes, making it easy for developers to work with data. Talend also provides strong support for big data processing and integration, making it a popular choice for organizations looking to leverage big data to drive their business forward.
12. ETL Pipe:
ETL Pipe is a flexible and scalable ETL framework that makes it easy to process large amounts of data. With its simple and intuitive API, ETL Pipe is an ideal choice for both beginners and experienced developers who want to extract, transform and load data into their data stores.
Some critical features of ETL Pipe include data flow visualization, quality checks, and support for a wide range of data sources and formats.
13. PyKEEN:
PyKEEN is an open-source Python library for performing knowledge graph embeddings. It is designed to be both fast and scalable, making it an ideal choice for large-scale data integration and analysis tasks.
Some key features of PyKEEN include support for TransE and ComplEx embeddings, automatic batching, and optimized GPU processing. Whether working on a research project or building a commercial solution, PyKEEN is an excellent choice for performing fast and efficient knowledge graph embeddings.
Comparison of Python ETL with traditional ETL tools
{{PythonETL="/components"}}
Real-world use cases of Python ETL in different industries:
Python has grown to be one of the most widely used programming languages. Due to its ease of use and adaptability, it is perfect for various applications.
Python's ability to execute ETL (extract, transform, and load) operations is one of the essential advantages of utilizing it for data processing, which is why many businesses have chosen it for their data management requirements. This post will examine a few Python ETL use scenarios in various businesses.
1. Healthcare
Managing patient data in the healthcare industry is crucial for effective treatment. Python ETL can help healthcare organizations extract patient data from disparate sources, transform it into a standardized format, and load it into a central repository for analysis.
This management helps healthcare providers make informed decisions based on data-driven insights and improve patient outcomes.
2. Finance:
Financial organizations deal with large amounts of data daily, making ETL a critical component of their data management strategy.
Python ETL can help banks, insurance companies, and other financial institutions extract data from various sources, including spreadsheets, databases, and APIs, and load it into a central repository for analysis.
This data management process helps financial organizations identify trends and make informed decisions that drive growth and profitability.
3. Retail:
Retail companies rely on data to make informed decisions about inventory management, sales trends, and customer behavior.
Python ETL can help retailers extract data from point-of-sale systems, websites, and other sources, transform it into a standard format and load it into a central repository for analysis. This further helps retailers make data-driven decisions that improve their bottom line.
4. Manufacturing:
Manufacturing companies generate large amounts of data from their production processes and machines. Python ETL can help these organizations extract data from various sources, such as sensors and machines, transform it into a standard format, and load it into a central repository for analysis.
This process helps manufacturers improve their production processes and make data-driven decisions that drive efficiency and profitability.
5. Telecommunications:
Telecommunications companies generate large amounts of data from their networks, systems, and customers. Python ETL can help these organizations extract data from various sources, such as call records and customer billing data, transform it into a standard format, and load it into a central repository for analysis.
This process helps telecommunications companies improve their networks, systems, and customer service.
To wrap it up, Python ETL has become a valuable tool for many industries, helping organizations extract data from various sources, transform it into a standard format, and load it into a central repository for analysis.
Whether in healthcare, finance, retail, manufacturing, or telecommunications, Python ETL can help you make data-driven decisions that drive growth and profitability. With its simplicity and versatility, it's no wonder that Python has become a popular choice for ETL operations.
Alternative programming languages for ETL
1. Java:

Java is one of the most often used programming languages for ETL processes. Java is a popular choice among developers because of its extensive ecosystem, which includes various ETL tools and frameworks. Java provides a solid and versatile ETL framework with exceptional speed and scalability. Furthermore, Java has a vast and lively community, making it simple to get help and support when needed.
2. Ruby:

Ruby is a dynamic, expressive programming language frequently used in ETL tasks. Ruby has a straightforward syntax that allows developers to interact with data quickly. Ruby also includes many ETL libraries and frameworks, making it a popular alternative for developers who want to get started quickly. Ruby is a versatile and scalable programming language that can easily handle big and complicated ETL tasks.
3. Go:

Go is a statically typed, compiled programming language often used for ETL projects. Go provides fast performance and efficient memory management, which makes it an attractive choice for ETL projects that require high performance. Go also has a simple and clean syntax, which makes it easy to learn and use. Additionally, Go has a growing and active community, which provides a wealth of resources and support for developers working with ETL.
Conclusion
Python ETL is a vital tool for transforming, loading, and processing data from several sources into a centralized data repository. Python has become a well-liked option for ETL systems due to its simple and adaptable syntax, many modules and frameworks, and strong community support.
Python for ETL allows developers to swiftly extract data from various sources, clean and modify it, and store it in a data warehouse. This strategy enables firms to grow, make informed decisions, and gain insightful information from their data.
This blog has discussed how to utilize Python for ETL and the benefits of Python ETL tools. We also looked at a few of the most popular Python ETL systems and their capabilities. We have discussed Java, Ruby, and Go as possible Python substitutes for ETL development.
In conclusion, Python ETL provides a reliable, flexible, and helpful framework for data processing and integration. Regardless of the developer's degree of experience, Python is an attractive choice for ETL systems. It offers several libraries and frameworks to aid in your speedy setup.
drives valuable insights
Organize your big data operations with a free forever plan
An agentic platform revolutionizing workflow management and automation through AI-driven solutions. It enables seamless tool integration, real-time decision-making, and enhanced productivity
Here’s what we do in the meeting:
- Experience Fynd Boltic's features firsthand.
- Learn how to automate your data workflows.
- Get answers to your specific questions.

%2520-%25204%2520Key%2520Differences%2520%2526%2520Principle%2520Architecture%2520(1).png)

.webp)